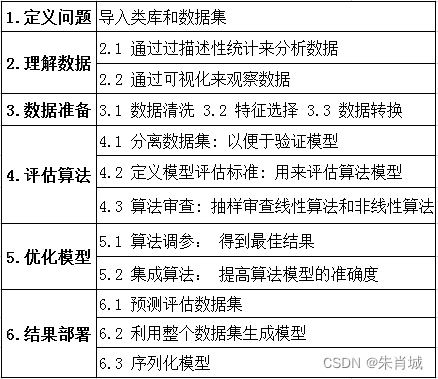
前端框架
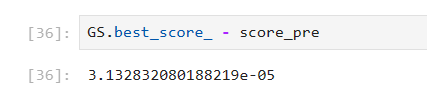
hadoop
SSD
一元函数微分学
lua __newindex
python 技巧
图像阴影检测
.net
文件
PDF加解密
栈
多模态
计算机毕业设计
如何修复网站漏洞
保险
滤波
盒子模型
图形化编程
php桶装水配送系统
引用类型
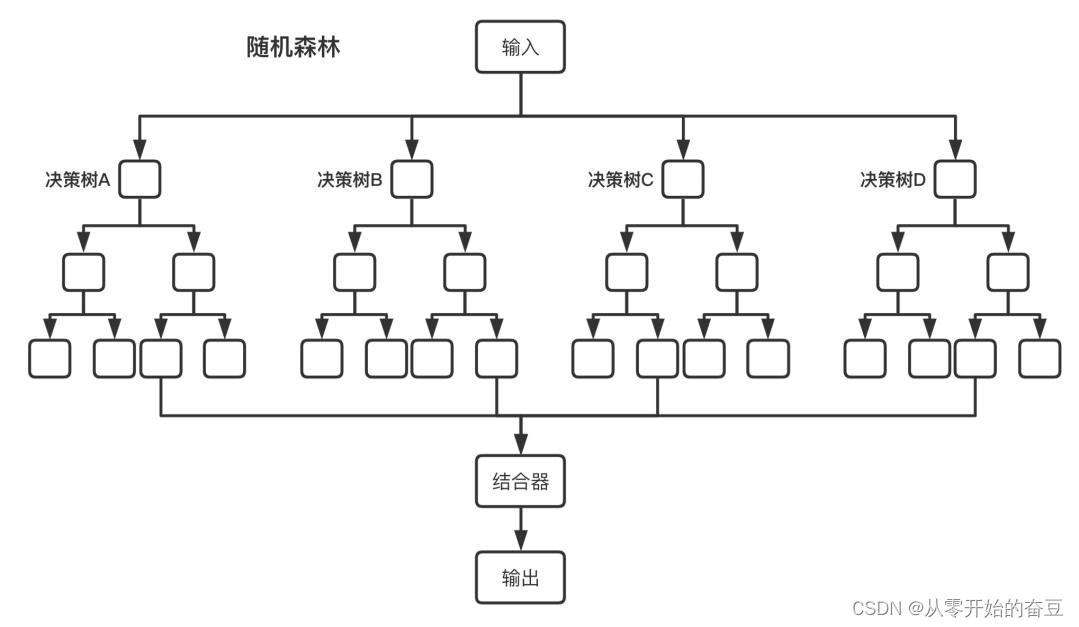
随机森林
2024/4/11 16:40:53
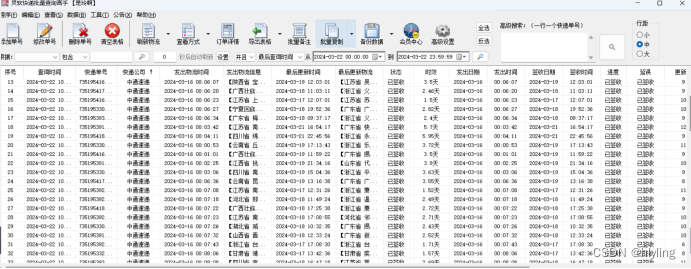
【需求研发001】--备品备件系统优化
1.PDA领料出库,拣配任务清单按创建日期自动排序
PDA的领料出库,虽然是在PDA设备里操作,但是它真正调用的,是备品备件生产环境的后端。
因此,这个需求,只需要改动生产环境的后端API,即可。
找…

educoder 机器学习之随机森林算法
第1关:Bagging
import numpy as np
from collections import Counter
from sklearn.tree import DecisionTreeClassifier
class BaggingClassifier():def __init__(self, n_model10):初始化函数#分类器的数量,默认为10self.n_model n_model#用于保存模…
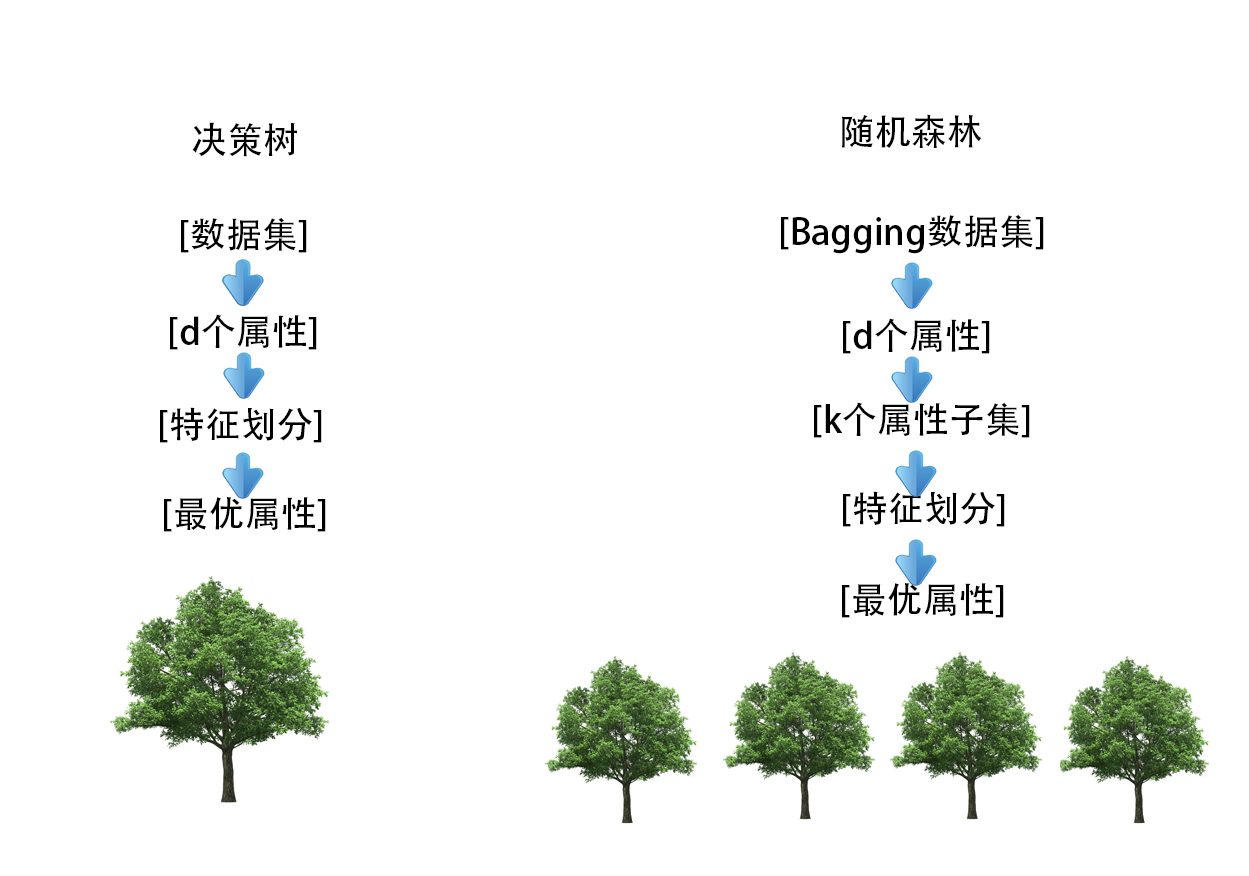
随机森林和决策树区别
随机森林(Random Forest)和决策树(Decision Tree)是两种不同的机器学习算法,其中随机森林是基于决策树构建的一种集成学习方法。以下是它们之间的主要区别:
决策树: 单一模型: 决策树是一种单一模型&#…
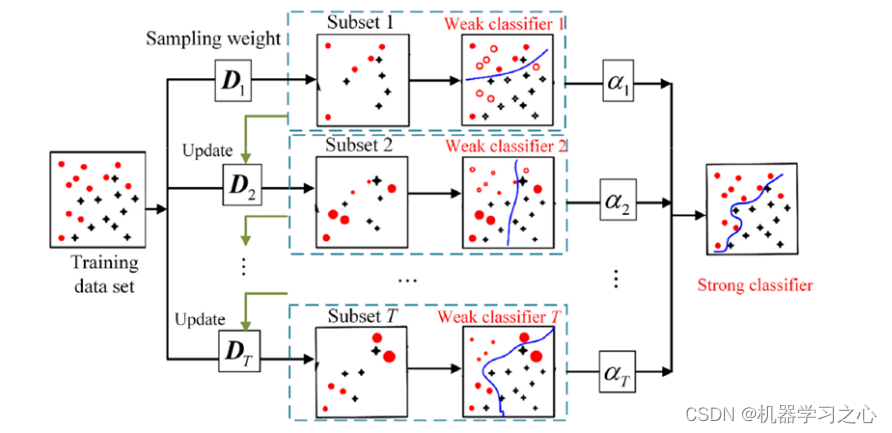
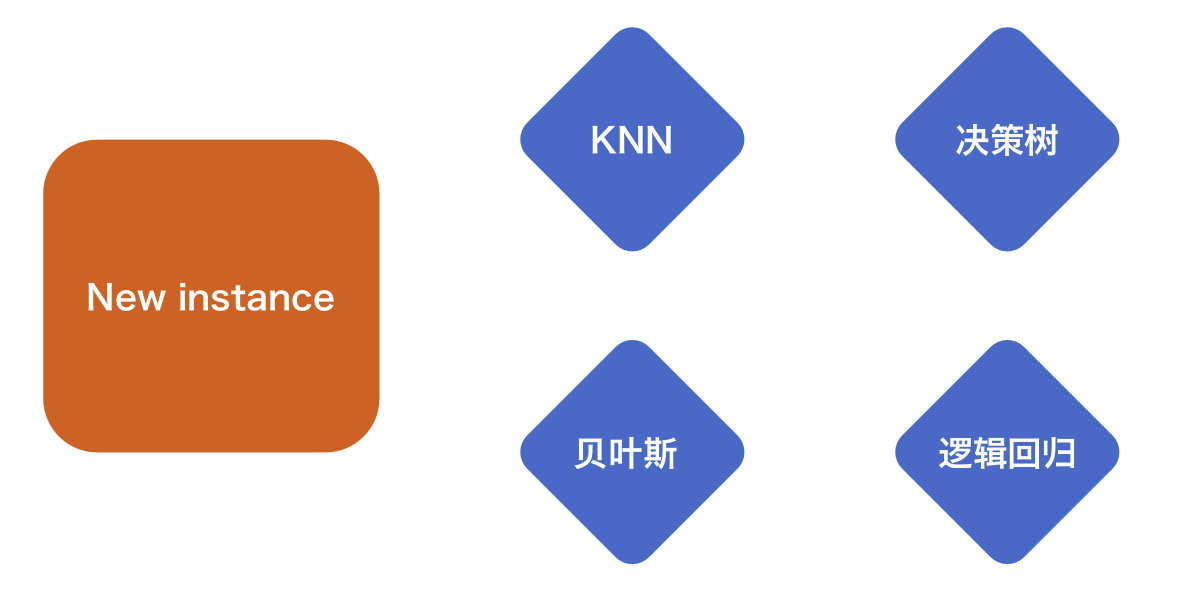
分类预测 | MATLAB实现基于RF-Adaboost随机森林结合AdaBoost多输入分类预测
分类预测 | MATLAB实现基于RF-Adaboost随机森林结合AdaBoost多输入分类预测 目录 分类预测 | MATLAB实现基于RF-Adaboost随机森林结合AdaBoost多输入分类预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.MATLAB实现基于RF-Adaboost随机森林结合AdaBoost多输…

数据分享|WEKA信贷违约预测报告:用决策树、随机森林、支持向量机SVM、朴素贝叶斯、逻辑回归...
完整报告链接:http://tecdat.cn/?p28579 作者:Nuo Liu 数据变得越来越重要,其核心应用“预测”也成为互联网行业以及产业变革的重要力量。近年来网络 P2P借贷发展形势迅猛,一方面普通用户可以更加灵活、便快捷地获得中小额度的贷…
GEE机器学习——利用随机森林RF方法进行土地分类和精度评定
随机森林方法
随机森林(Random Forest,RF)是一种集成学习方法,用于解决分类和回归问题。它由多个决策树组成,每个决策树都是一个独立的分类器。通过对每个决策树的预测结果进行集成,随机森林能够提供更准确和稳定的预测。
随机森林的主要特点包括:
1. 随机特征选择:…

PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像...
原文链接:http://tecdat.cn/?p24346 在今天产品高度同质化的品牌营销阶段,企业与企业之间的竞争集中地体现在对客户的争夺上(点击文末“阅读原文”获取完整代码数据)。 “用户就是上帝”促使众多的企业不惜代价去争夺尽可能多的客…

Web安全之机器学习 | 决策树与随机森林算法
决策树算法
1、决策树算法概述
决策树表现了对象属性与对象值之间的一种映射关系。决策树中每个节点表示某个对象,而每个分叉路径则代表某个可能的属性值,每个叶节点则对应从根节点到该叶节点所经历的路径所表示的对象值。决策树可以用于数据分类也可以…

opencv 进阶20-随机森林示例
OpenCV中的随机森林是一种强大的机器学习算法,旨在解决分类和回归问题。随机森林使用多个决策树来进行预测,每个决策树都是由随机选择的样本和特征组成的。在分类问题中,随机森林通过投票来确定最终的类别;在回归问题中࿰…

选择和训练模型(Machine Learning 研习之十一)
当您看到本文标题时,不禁感叹,总算是到了训练模型这一节了。 是啊,在之前的文章中,我们对数据进行了探索,以及对一个训练集和一个测试集进行了采样,也编写了一个预处理管道来自动清理,准备您的数…
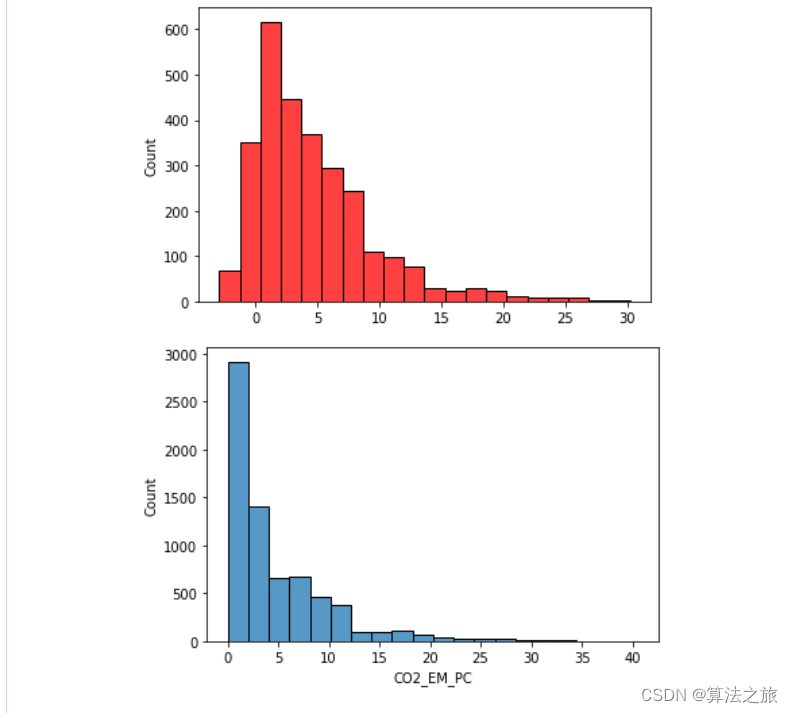
碳排放预测模型 | Python实现基于RF随机森林的碳排放预测模型
文章目录 效果一览文章概述研究内容源码设计参考资料效果一览 文章概述 碳排放预测模型 | Python实现基于RF随机森林的碳排放预测模型 研究内容 碳排放被认为是全球变暖的最主要原因之一。 该项目旨在提供各国碳排放未来趋势的概述以及未来十年的全球趋势预测。 其方法是分析这…

【机器学习】集成学习(以随机森林为例)
文章目录 集成学习随机森林随机森林回归填补缺失值实例:随机森林在乳腺癌数据上的调参附录参数 集成学习
集成学习(ensemble learning)是时下非常流行的机器学习算法,它本身不是一个单独的机器学习算法,而是通过在数据…
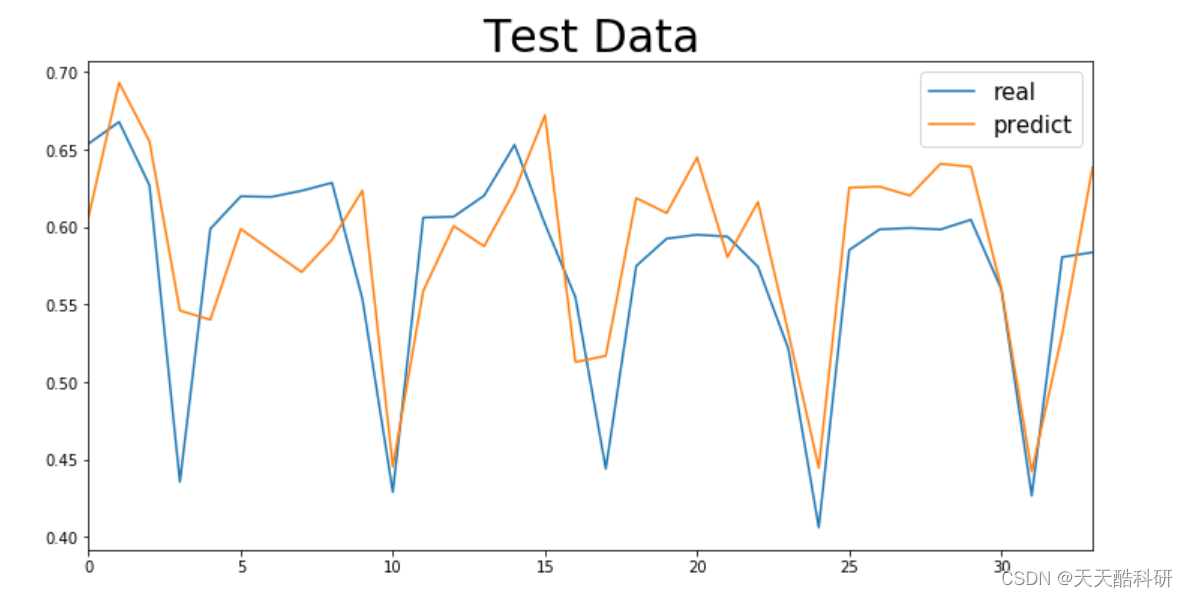
电力负荷预测 | 电力系统负荷预测模型(Python线性回归、随机森林、支持向量机、BP神经网络、GRU、LSTM)
文章目录 效果一览文章概述源码设计参考资料效果一览 文章概述 电力系统负荷预测模型(Python线性回归、随机森林、支持向量机、BP神经网络、GRU、LSTM) 所谓预测,就是指通过对事物进行分析及研究,并运用合理的方法探索事物的发展变化规律,对其未来发展做出预先估计和判断。…

故障诊断 | 一文解决,RF随机森林的故障诊断(Matlab)
效果一览 文章概述 故障诊断 | 一文解决,RF随机森林的故障诊断(Matlab) 模型描述
随机森林(Random Forest)是一种集成学习(Ensemble Learning)方法,常用于解决分类和回归问题。它由多个决策树组成,每个决策树都独立地对数据进行训练,并且最终的预测结果是由所有决策…

各类机器学习方法的应用场景是什么?
作者:xyzh 链接:https://www.zhihu.com/question/26726794/answer/151282052 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:xyzh 链接:https://www.zhihu.com/…

AMEYA:ROHM新增5款100V耐压双MOSFET,实现业界超低导通电阻
全球知名半导体制造商ROHM(总部位于日本京都市)面向通信基站和工业设备等的风扇电机驱动应 用,开发出将两枚100V耐压MOSFET* 1一体化封装的双MOSFET新产品。新产品分“HP8KEx/HT8KEx (NchNch)系列”和“HP8MEx(NchPch*2)系列”两个系列,共5款新机型。 近…
6、机器学习之随机森林
使用更复杂的机器学习算法。 本课程所需数据集夸克网盘下载链接:https://pan.quark.cn/s/9b4e9a1246b2 提取码:uDzP 文章目录 1、简介2、实例3、结论 1、简介
决策树给你留下了一个困难的选择。一个深度很大、有很多叶子的树会因为每个预测都来自其叶子…
【代码】基于算术优化算法(AOA)优化参数的随机森林(RF)六分类机器学习预测算法/matlab代码
代码名称:基于算术优化算法(AOA)优化参数的随机森林(RF)六分类机器学习预测算法/matlab代码
使用算术优化算法(AOA)优化分类预测模型的参数,收敛性好,准确率提升明显&am…
2023年数学建模:随机森林:基于多个决策树的集成学习方法
2023年9月数学建模国赛期间提供ABCDE题思路加Matlab代码,专栏链接(赛前一个月恢复源码199,欢迎大家订阅):http://t.csdn.cn/Um9Zd
目录
1. 随机森林原理
1.1 随机选取训练样本
1.2 随机选取特征
2. 特征选择
2.1 平均不纯度减少
2.2 平均精度减少
3. 随机森林的优缺点 …
随机森林的视觉应用-Regression Forests (2)
我个人觉得具有时代意义的文章是J. Gall的Hough Forests,regression forests这个概念已经很多年,但是近几年在视觉中应用的regression forests本质是HF。Gall原来在ETH Zrich Computer Vision Laboratory,即Luc Van …
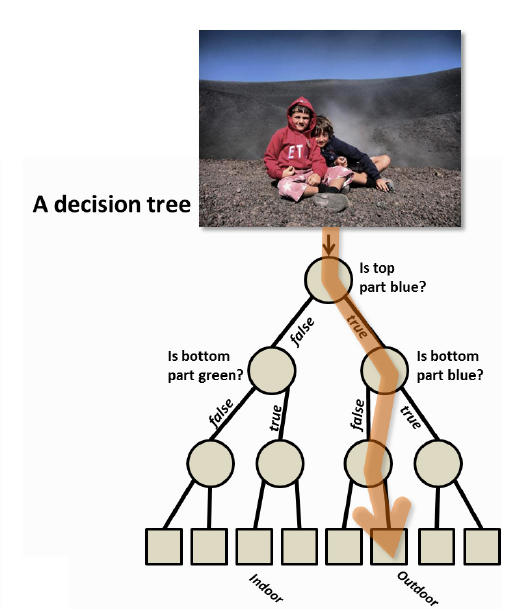
谈谈随机森林的视觉应用-Random Forests(1)
写这个东西是我开此博客的动机,也是我第一次用中文阐述关于自己研究的东西。写得不好请各位包涵!
(关于这个名字的中文翻译,我一向觉得非常的别扭,所以在博文中我继续使用其英文名称…
GEE土地分类——使用随机森林方法和多源遥感数据进行面向对象的土地分类NAIP数据为例
简介: 数据:
国家农业图像计划 (NAIP) 在美国大陆的农业生长季节获取航空图像。
NAIP 项目每年根据可用资金和图像获取周期签订合同。从 2003 年开始,NAIP 以 5 年为一个周期。2008 年是过渡年,2009 年开始采用 3 年周期。
NAIP 图像以一米的地面采样距离 (GSD) 采集,水…
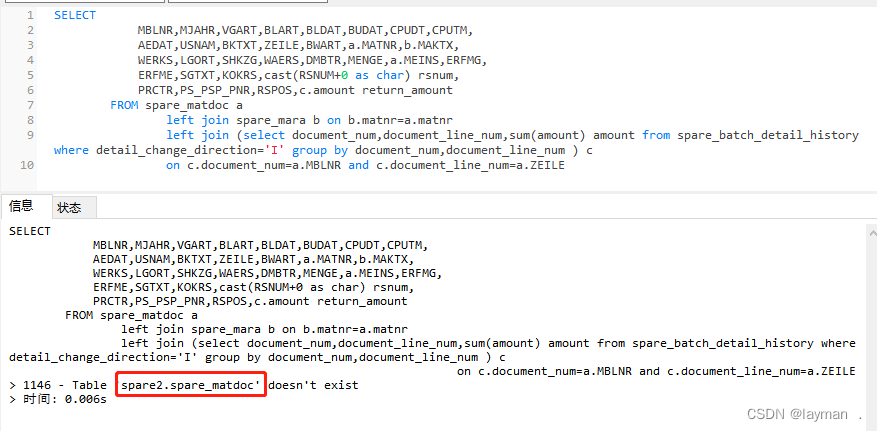
【备品备件】入库流程--赠品入库,商贸入库和退库入库
赠品入库
前台页面:GiftsWarehousing.vue 方法:listZprk
前台js文件:zprk.js
查询方法对应的后台类:SpareZprkController 查询参数:ZZPJH
查询方法对应的SQL语句:
select ZZPJH, BUKRS, WERKS, CGHTH,…
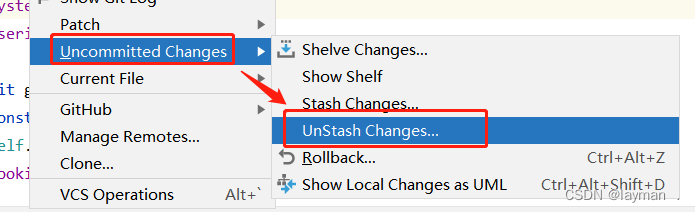
【设备管理系统】-部署到正式环境
后端比较简单,只有一个master分支,直接变更就行了。
前端比较麻烦一点,有2个分支,一个dev分支(测试环境),一个master分支(正式环境),而且两个分支的代码还不…
台大林轩田机器学习技法集成学习完全解读
Blending与Bagging
Adaboost
决策树(Decision Tree)
随机森林(Random Forest)
梯度提升树(GBDT)
最后感谢林轩田老师!
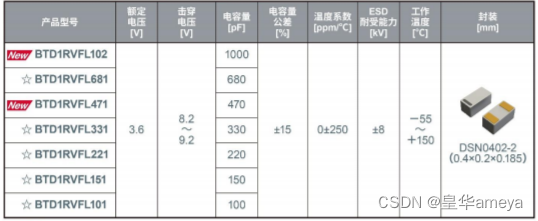
AMEYA360|ROHM罗姆首次推出硅电容器BTD1RVFL系列
全球知名半导体制造商ROHM(总部位于日本京都市)新开发出在智能手机和可穿戴设备等领域应用日益广泛的硅电容器。利用ROHM多年来积累的硅半导体加工技术,新产品同时实现了更小的尺寸和更高的性能。 随着智能手机等应用的功能增加和性能提升,业界对于支持更…
随机森林 {Keras 由浅入深}
随机森林
TensorFlowKerassklearn
python & mathematics 随机森林是集成学习中的一种方法。 随机森林采用的方法为bagging(样本不放回) from sklearn.ensemble import RandomForestClassifier可参考链接: https://www.cnblogs.com/zongf…
机器学习算法(9)——集成技术(Bagging——随机森林分类器和回归)
一、说明 在这篇文章,我将向您解释集成技术和著名的集成技术之一,它属于装袋技术,称为随机森林分类器和回归。 集成技术是机器学习技术,它结合多个基本模块和模型来创建最佳预测模型。为了更好地理解这个定义,我们需要…
机器学习之决策树及随机森林
决策树
概念
决策树(Decision Tree)是一种常见的机器学习算法,用于分类和回归任务。它是一种树状结构,其中每个内部节点表示一个特征或属性,每个分支代表一个决策规则,而每个叶节点表示一个输出标签或值。
构建决策树过程
构建决策树的过程通常涉及以下步骤: 数据准…

【机器学习】P24 随机森林算法(1) 实现 “鸢尾花” 预测
随机森林算法 Random Forest Algorithm 随机森林算法随机森林算法实现分类鸢尾花 随机森林算法
随机森林(Random Forest)算法 是一种 集成学习(Ensemble Learning)方法,它由多个决策树组成,是一种分类、回…
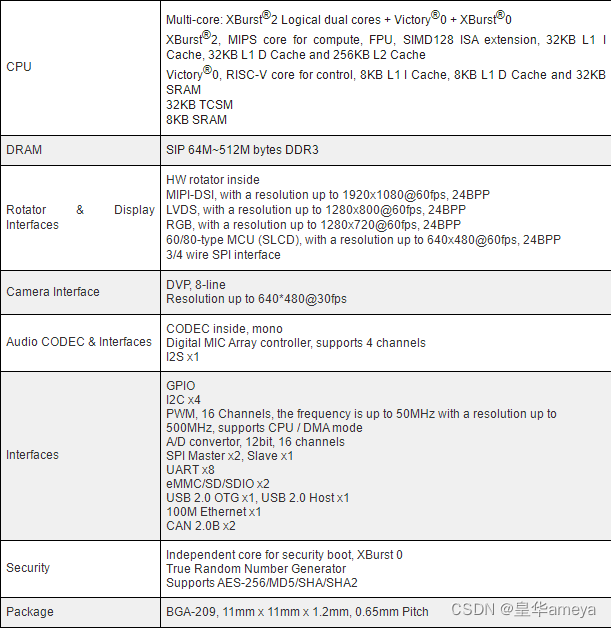
AMEYA360:君正低功耗AIoT图像识别处理器—X1600/X1600E
• 高性能 XBurst 1 CPU,主频1.0GHz • 超低功耗 • 内置LPDDR2(X1600:32MB,X1600E:64MB) • 实时控制核XBurst 0,面向安全管理和实时控制 • 丰富的外设接口 应用领域 • 基于二维码的智能商业 • 智能物联网 • 高端…
随机森林 2(决策树)
通过 随机森林 1 的介绍,相信大家对随机森林都有了一个初步的认知,知道了随机和森林分别指的是什么,以及决策树根据什么选择内部节点。本文将会从森林深入到树,去看一下决策树是如何构建的。网上很多文章都讲了决策树如何构建&…
sklearn - 决策树和随机森林
文章目录决策树回归模型决策树分类器可视化随机森林分类器特征重要性选择随机森林中的重要特征处理不均衡的分类控制决策树的规模通过 boosting 提高性能使用袋外误差(Out-of-bag Error)评估随机森林模型决策树回归模型 from sklearn import datasets
f…
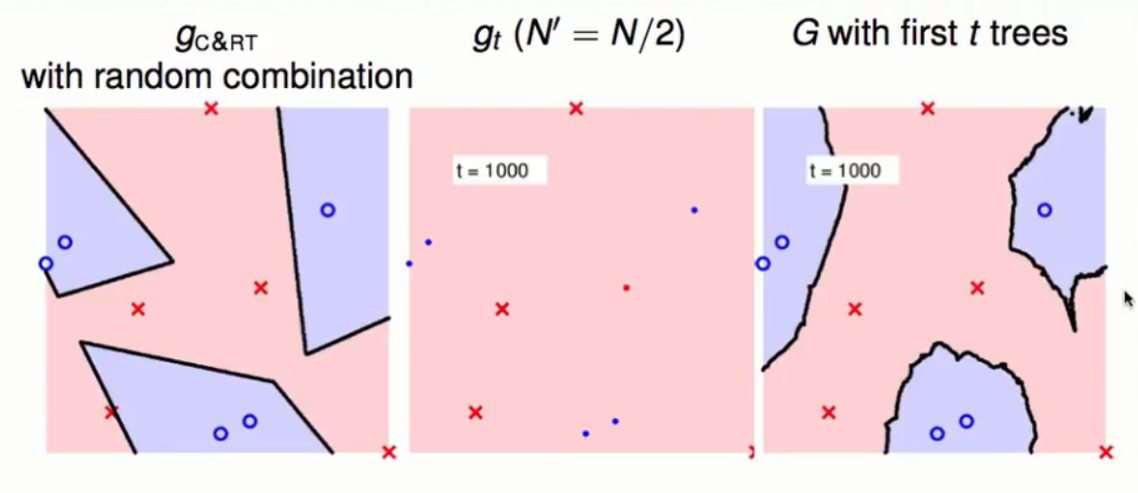
机器学习之随机森林(机器学习技法)
随机森林(RandomForest)
集成学习中的Bagging通过bootstrapping的方式进行抽取不同的资料从每一堆资料中学得一个小的模型g,然后再将这些小的模型进行融合进而得到一个更为稳定的大的模型G。决策树模型通过递归的方式按照某些特征进行分支得到…

时序预测 | Matlab实现基于RF随机森林的电力负荷预测模型
文章目录 效果一览基本介绍模型描述源码设计学习小结参考资料效果一览 基本介绍 时序预测 | Matlab实现基于RF随机森林的电力负荷预测模型 电力负荷预测是指通过对历史电力负荷数据分析,来预测未来某个时间段内的电力负荷需求。这项预测对于电力系统的运行和调度至关重要,可以…

贝叶斯优化 | BO-RF贝叶斯优化随机森林多输入单输出回归预测(Matlab完整程序)
贝叶斯优化 | BO-RF贝叶斯优化随机森林多输入单输出回归预测(Matlab完整程序) 目录 贝叶斯优化 | BO-RF贝叶斯优化随机森林多输入单输出回归预测(Matlab完整程序)预测结果基本介绍评价指标程序设计参考资料预测结果 基本介绍 贝叶斯优化 | BO-RF贝叶斯优化随机森林多输入单…
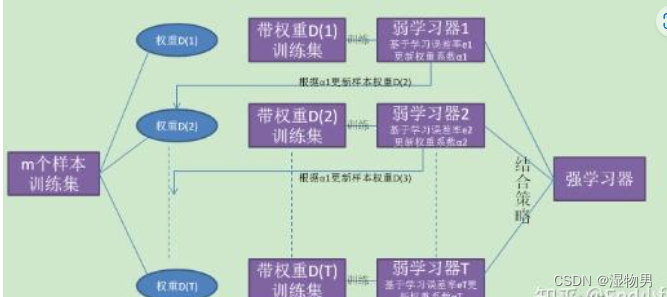
树模型(2)随机森林
随机森林属于集成学习中bagging算法的延展,所以先来介绍一下集成学习。
**集成学习:**对于训练数据集,我们通过训练一系列个体学习器,并通过一定的结合策略将它们组合起来,形成一个强有力的学习器
**个体学习器&…
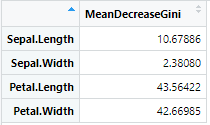
基于R语言和iris数据集实现随机森林模型及测试应用
基于R语言和iris数据集实现随机森林模型及测试应用 测试应用R代码
#加载随机森林模型库
> library("randomForest")
#加载iris数据集
> data(iris)
> head(iris)# 设置训练数据和标签
t_data <- iris[, -5]
t_labels <- iris[, 5] # 训练随机森…
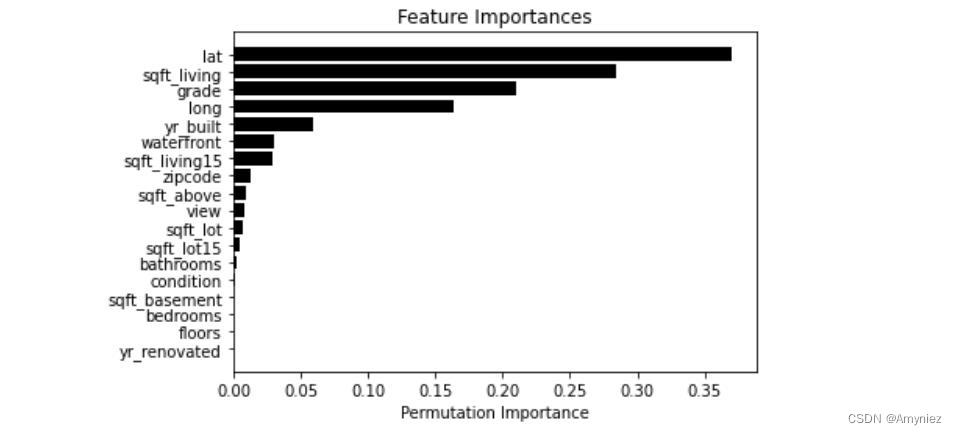
机器学习笔记 十八:基于3种方法的随机森林模型分析房屋参数重要性
这里写自定义目录标题1. 探索性数据分析1.1 数据集分割(训练集、测试集)1.2 模型拟合2. 特征重要性比较2.1 Gini Importance2.2 Permutation Importance2.3 Boruta3. 特征比较3.1 Gini Importance3.2 Permutation Importance3.3 Boruta4. 模型比较将机器…
机器学习-面经(part8、贝叶斯和其他知识点)
机器学习面经其他系列 机器学习面经系列的其他部分如下所示:
机器学习-面经(part1)-初步说明
机器学习-面经(part2)-交叉验证、超参数优化、评价指标等内容
机器学习-面经(part3)-正则化、特征工程面试问题与解答合集机器学习-面经(part4)-决策树共5000字的面试问…
2023年数学建模随机森林:基于多个决策树的集成学习方法
2023年9月数学建模国赛期间提供ABCDE题思路加Matlab代码,专栏链接(赛前一个月恢复源码199,欢迎大家订阅):http://t.csdn.cn/Um9Zd
目录
目录
1. 什么是随机森林?
2. 随机森林的优缺点
3. 随机森林的构建过程
4. 特征选择
5. MATLAB实现随机森林
6. 数学建模…

微调模型——续(Machine Learning 研习之十三)
集成方法
微调系统的另一种方法是尝试组合性能最佳的模型。 群体(或“整体”)通常会比最好的单个模型表现得更好,就像随机森林比它们所依赖的单个决策树表现更好一样,特别是当各个模型犯下不同类型的错误时。 例如,您…
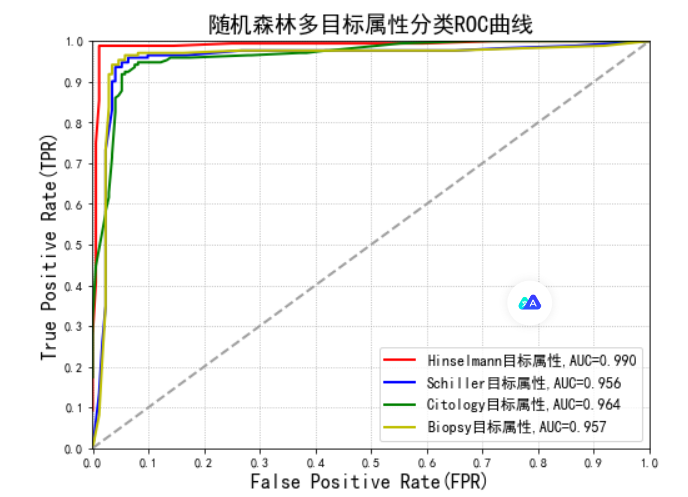
机器学习---随机森林宫颈癌分类
1. 宫颈癌分类
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import Pipeline
from sklearn.preprocessi…
机器学习中的算法(1)-决策树模型组合之随机森林与GBDT
原文地址为:
机器学习中的算法(1)-决策树模型组合之随机森林与GBDT版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleastgm…
模式识别与机器学习(十二):随机森林
原理
随机森林(Random Forest, RF)是Bagging的一个扩展变体。RF在以决策树为基学习器构建Bagging集成的基础上,在决策树的训练过程中引入随机属性选择。训练每颗决策树时随机选出部分特征作为输入,所以该算法被称为随机森林算法。
在RF中,对…

随机森林的简单学习记录
随机森林小记
这里采用的随机森林的库选择sklearn库
1.首先是导入数据:
path "D:/Epileptic Seizure Classification.csv"
# 针对csv文件
rawdata pd.read_csv(path)
# 针对xlsx文件
rawdata pd.read_excel(path) 2.根据数据分布,选出样…
机器学习的算法简单介绍-随机森林算法
随机森林
随机森林目前在学习的过程中,并未使用到,因此,仅仅简单的介绍一下相应的概念和应用的方面,等后续学习的过程中使用到,会继续进行补充。
随机森林(Random Forest)可以看作是一种集成学…
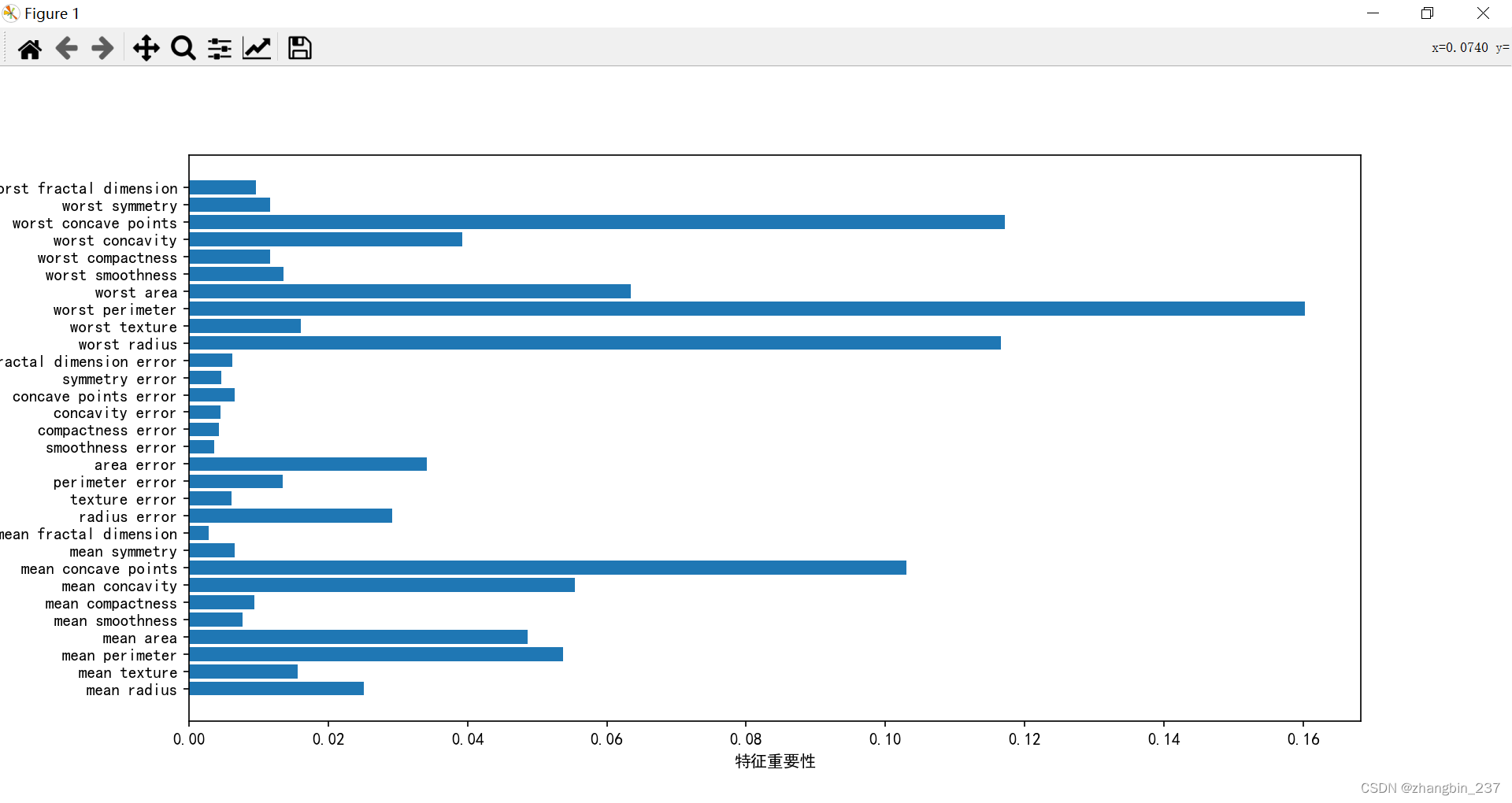
【Python机器学习】决策树集成——随机森林
理论知识:
集成是合并多个机器学习模型来构建更强大模型法方法。
随机森林本质上是许多决策树的集合,其中每棵树都和其他数略有不同,随机森林背后的思想是:每棵树的预测可能都比较好,但是可能对部分数据过拟合&#…
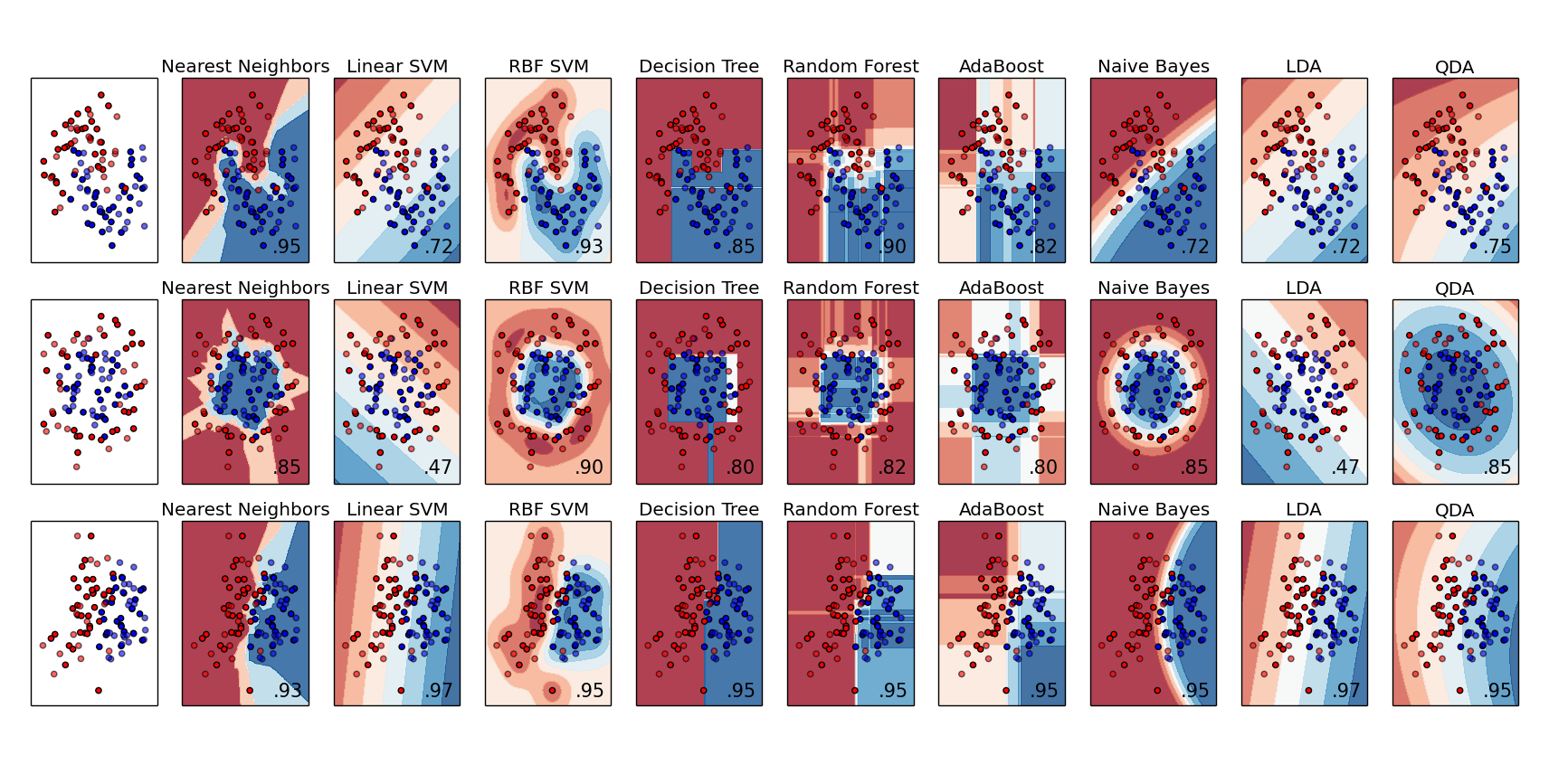
机器学习算法(二)-随机森林
文章转自:[Machine Learning & Algorithm] 随机森林(Random Forest) 1 什么是随机森林? 作为新兴起的、高度灵活的一种机器学习算法,随机森林(Random Forest,简称RF)拥有广泛的应…
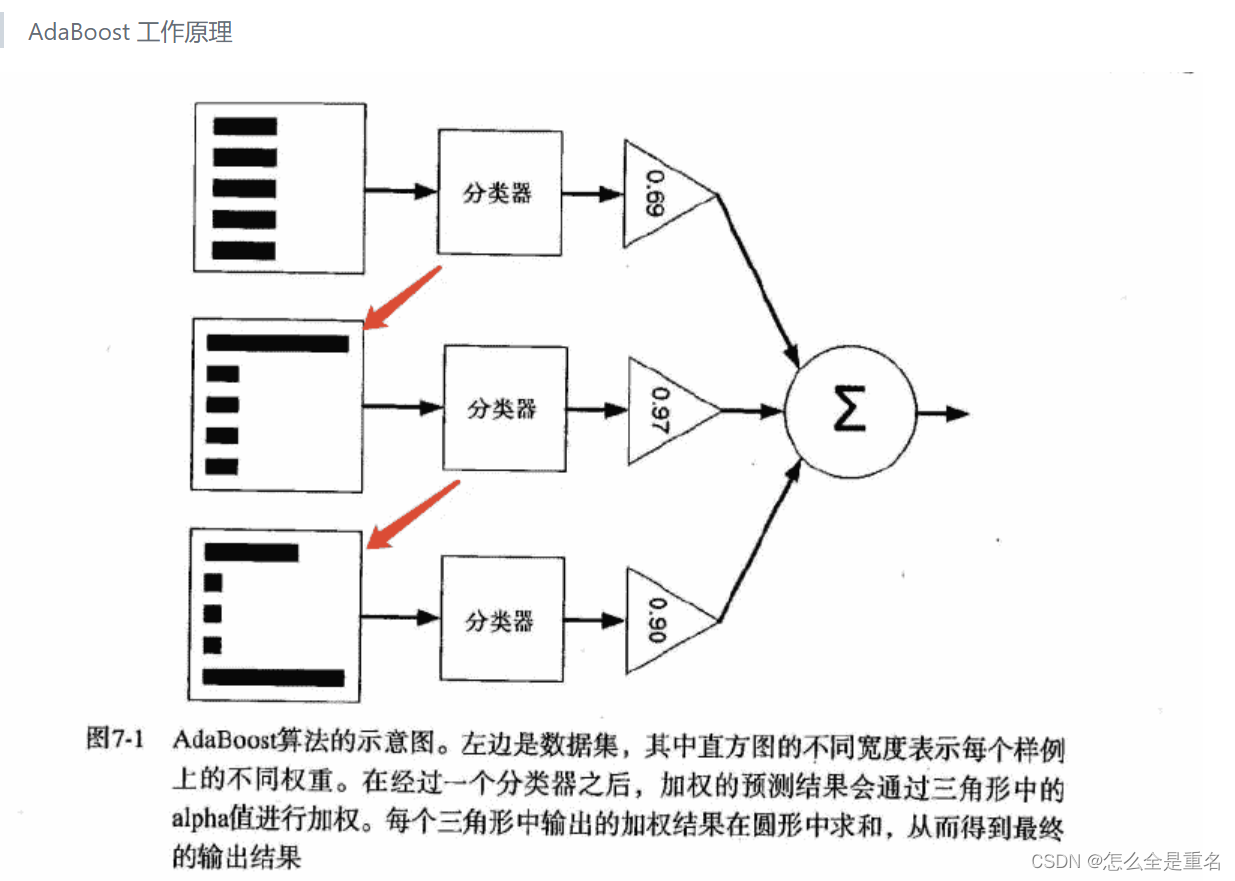
集成学习方法(随机森林和AdaBoost)
释义
集成学习很好的避免了单一学习模型带来的过拟合问题 根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类:
Bagging(个体学习器间不存在强依赖关系、可同时生成的并行化方法) 流行版本:随机森林(random forest)Boosting(个体…
重塑林业管理:山海鲸可视化软件为智慧林业赋能
作为山海鲸可视化软件的开发者,我们深知林业行业在数据可视化和管理方面的需求。因此,在不断升级山海鲸可视化这款可以免费编辑、部署的产品同时,我们针对各行可视化需求,推出各行可视化解决方案。
针对林业管理可视化需求&#…
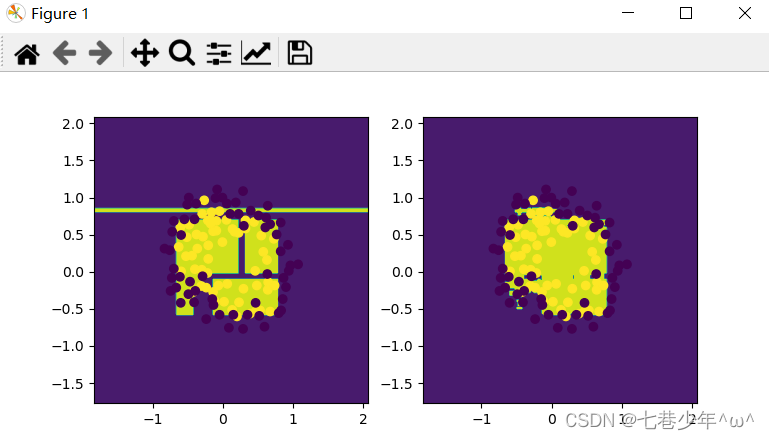
第七章.集成学习(Ensemble Learning)—袋装(bagging),随机森林(Random Forest)
第七章.集成学习 (Ensemble Learning) 7.1 集成学习—袋装(bagging),随机森林(Random Forest)
集成学习就是组合多个学习器,最后得到一个更好的学习器。 1.常见的4种集成学习算法
个体学习器之间不存在强依赖关系,袋装(bagging)…
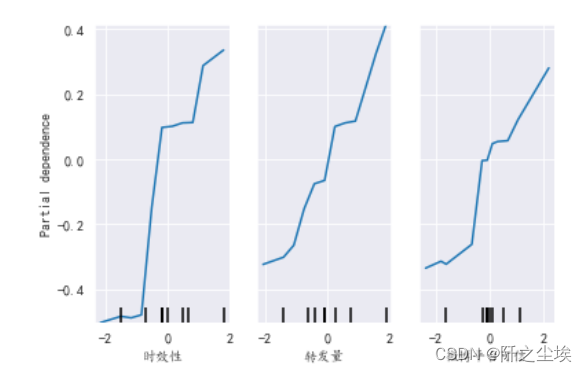
Python数据分析案例22——财经新闻可信度分析(线性回归,主成分回归,随机森林回归)
本次案例还是适合人文社科领域,金融或者新闻专业。本科生做线性回归和主成分回归就够了,研究生还可以加随机森林回归,其方法足够人文社科领域的硕士毕业论文了。 案例背景
有八个自变量,[微博平台可信度,专业性,可信赖性,转发量,…
机器学习——随机森林【手动代码】
随机森林这个内容,是目前来说。。。最最最简单,最好理解,应该也是最好实现的了!!! 先挖坑,慢慢填 随机森林,这个名字取得,果然深得该算法的核心精髓,既随机&a…
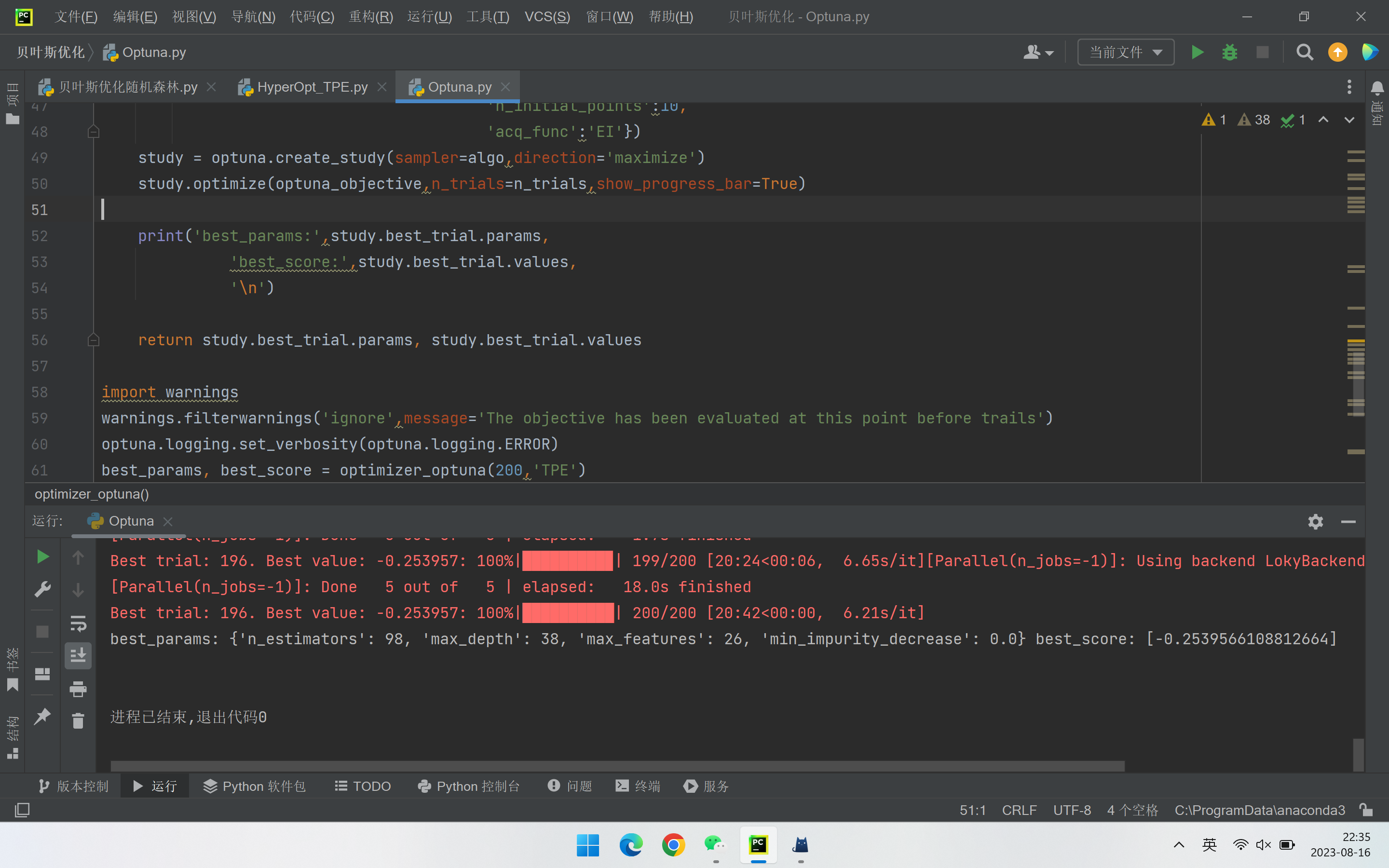
数据分析 | 调用Optuna库实现基于TPE的贝叶斯优化 | 以随机森林回归为例
1. Optuna库的优势 对比bayes_opt和hyperoptOptuna不仅可以衔接到PyTorch等深度学习框架上,还可以与sklearn-optimize结合使用,这也是我最喜欢的地方,Optuna因此特性可以被使用于各种各样的优化场景。 2. 导入必要的库及加载数据 用的是sklea…
Sklearn-RandomForest随机森林参数及实例
本文转载至Sklearn-RandomForest随机森林参数及实例
在scikit-learn中,RandomForest的分类类是RandomForestClassifier,回归类是RandomForestRegressor,需要调参的参数包括两部分,第一部分是Bagging框架的参数,第二部…


集成学习方法之随机森林-入门
1、 什么是集成学习方法
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。
2、 什么是随机森林
在机器学习中&…
探索随机森林: 机器学习中的集成学习神器
机器学习 第七课 随机森林 概述机器学习机器学习的主要分类监督学习无监督学习强化学习 集成学习提高准确性增强稳定性提升泛化能力 集成学习的主要方法BaggingBoostingStacking 随机森林的理论基础决策树的基本原理随机森林的生成过程随机森林的优势与局限性 随机森林的实际应…
基于随机森林的机器启动识别,基于随机森林的智能家居电器启动识别
目录 背影 摘要 随机森林的基本定义 随机森林实现的步骤 基于随机森林的机器启动识别 代码下载链接: 基于随机森林的家用电器启动识别,基于RF的电器启动识别,基于随机森林的智能家居启动检测-深度学习文档类资源-CSDN文库 https://download.csdn.net/download/abc991835105/…

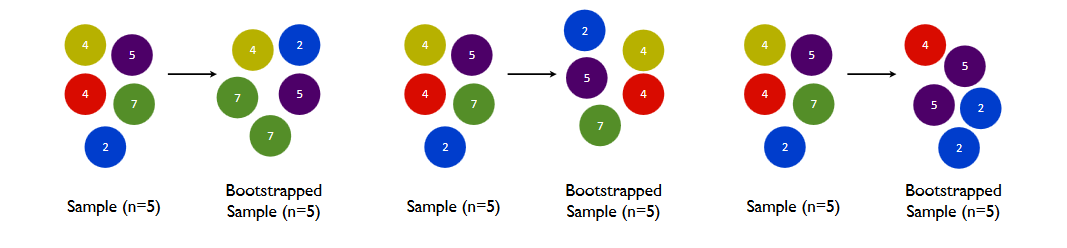
随机森林--Bagging算法的典型代表
一:Bootstrap方法简介
简称自助法,是一种有放回的抽样方法,他是非参数统计中一种重要的方法,通过估计样本方差,进而对总体的分布特性进行统计推断。首先,Bootstrap通过重抽样(通过boostrap 采样…
随机森林(原理/样例实现/参数调优)
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/y0367/article/details/51501780
决策树
1.决策树与随机森林都属于机器学习中监督学习的范畴,主要用于分类问题。 决策树算法有这几种:ID3、C4.5、…

python:使用随机森林回归模型进行数据预测
作者:CSDN @ _养乐多_
在本篇博客中,我们将介绍如何使用Python编程语言和一些主要的数据科学工具(pandas、numpy、sklearn等)来进行数据预测。我们将使用随机森林回归模型,该模型是一种强大的机器学习算法,适用于回归问题,例如预测连续性变量的值。我们将演示如何准备数…
基于变态模态分解+bp-rf的轴承故障分类,基于变态模态分解的+BP神经网络-随机森林的轴承故障分类
目录 背影 摘要 随机森林的基本定义 随机森林实现的步骤 基于随机森林的机器启动识别 代码下载链接: 基于变态模态分解+bp-rf的轴承故障分类,基于变态模态分解的+BP神经网络-随机森林的轴承故障分类(代码完整,数据齐)资源-CSDN文库 https://download.csdn.net/download/ab…

机器学习 day38(有放回抽样、随机森林算法、XGBoost)
有放回抽样
有放回抽样和无放回抽样的区别:有放回可以确保每轮抽取的结果不一定相同,无放回则每轮抽取的结果都相同 在猫狗的例子中,我们使用”有放回抽样“来抽取10个样本,并组合为一个与原始数据集不同的新数据集,虽…
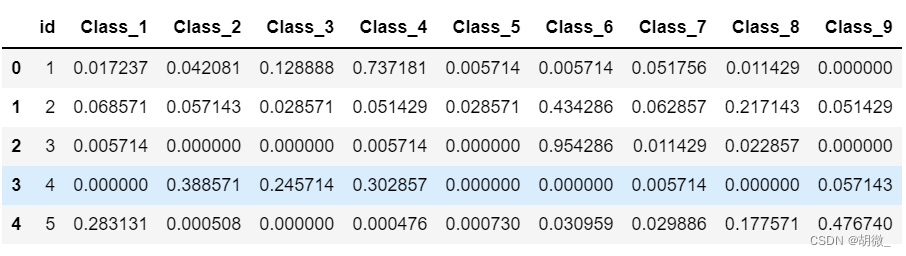
随机森林应用案例 —— otto产品分类
otto产品分类1 案例背景2 数据集介绍3 评分标准4 流程实现4.1 获取数据集4.2 数据基本处理4.3 模型训练4.4 模型评估4.5 模型调优4.6 生成提交数据1 案例背景
奥托集团是世界上最大的电子商务公司之一,在20多个国家设有子公司。该公司每天都在世界各地销售数百万种…
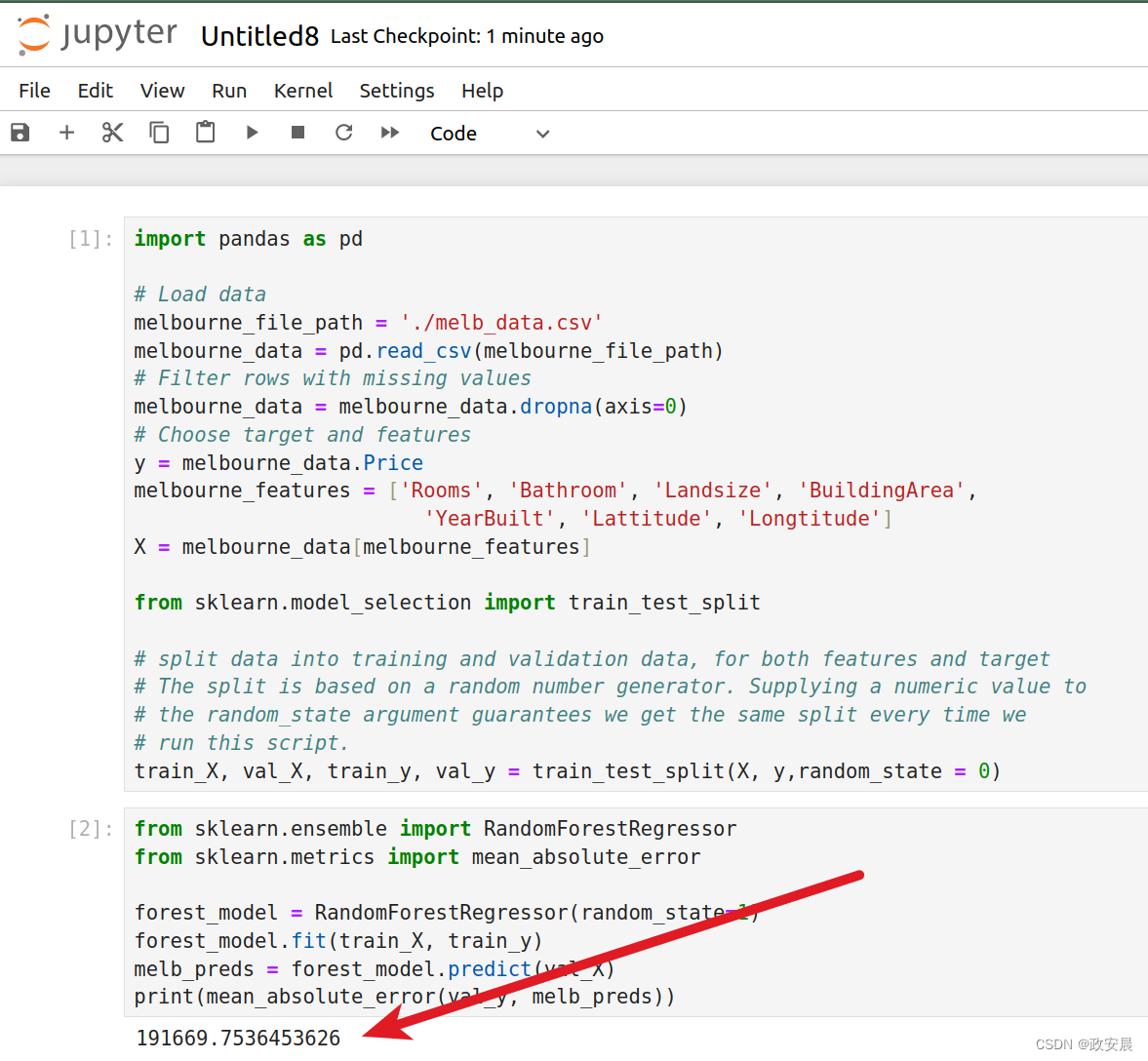
政安晨:机器学习快速入门(四){pandas与scikit-learn} {随机森林}
咱们将在这篇文章中使用更复杂的机器学习算法。 随机森林
基本定义
随机森林(Random Forest)是一种机器学习算法,属于集成学习(ensemble learning)的一种。它是通过构建多个决策树(即森林)来进行预测和分类的。
随机森林的主要特点是采用了…
Python房价分析(二)随机森林分类模型
目录
1 数据预处理
1.1 房价数据介绍
1.2 数据预处理
1.2.1 缺失值处理
1.2.2异常值处理
1.2.3 数据归一化
1.2.4 分类特征编码
2 随机森林模型
2.1 模型概述
2.2 建模步骤
2.3 参数搜索过程
3模型评估
3.1 模型评估结果
3.2 混淆矩阵
3.3 绘制房价类别三分类的…

【GEE笔记】随机森林特征重要性计算并排序
随机森林是一种基于多个决策树的集成学习方法,可以用于分类和回归问题。在gee中可以使用ee.Classifier.smileRandomForest()函数来创建一个随机森林分类器,并用它来对影像进行分类。
随机森林分类器有一个重要的属性,就是可以计算每个特征&a…
MATLAB实现随机森林回归算法
随机森林回归是一种基于集成学习的机器学习算法,它通过组合多个决策树来进行回归任务。随机森林的基本思想是通过构建多个决策树,并将它们的预测结果进行平均或投票来提高模型的准确性和鲁棒性。
以下是随机森林回归的主要特点和步骤: 决策树…
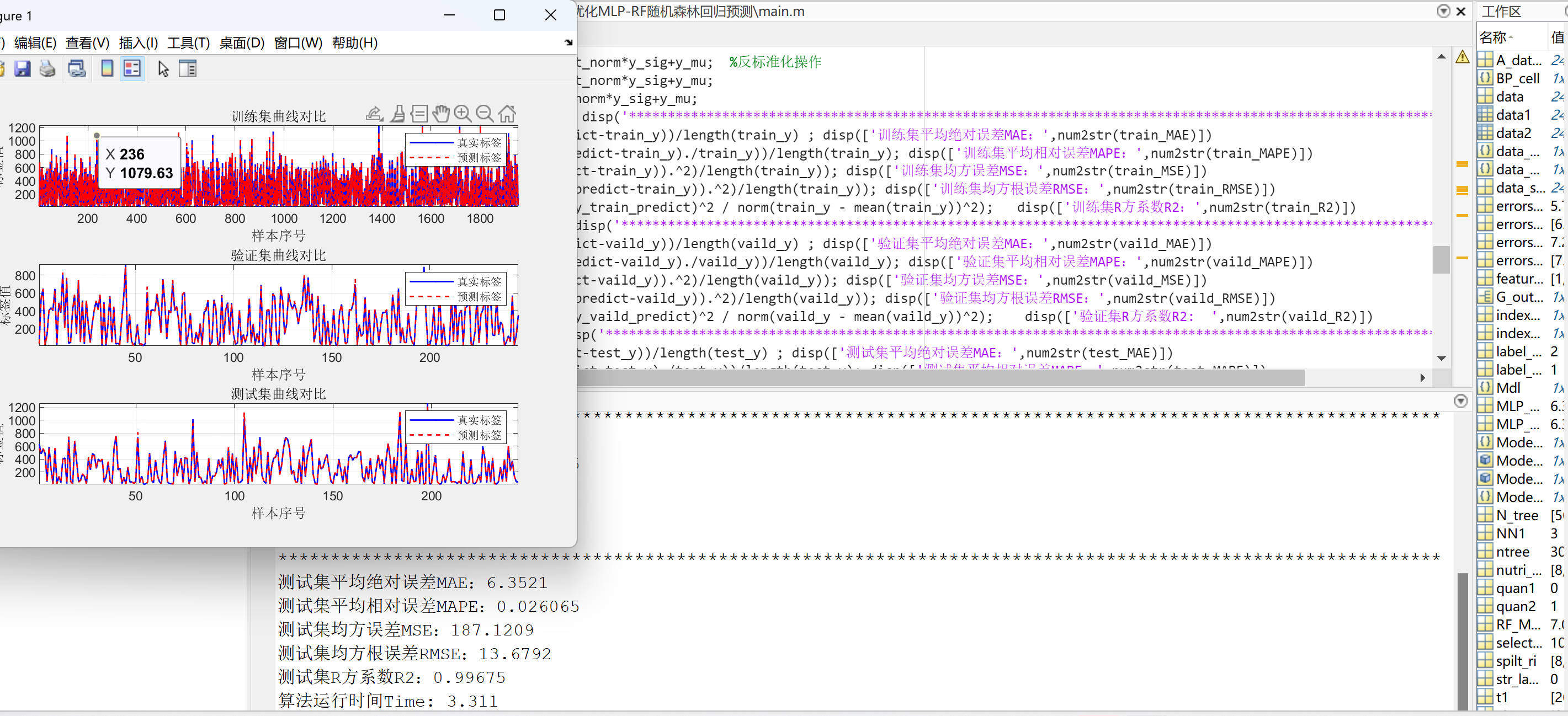
MLP-RF随机森林回归预测(matlab代码)
MLP-RF随机森林回归预测matlab代码
数据为Excel股票预测数据。
数据集划分为训练集、验证集、测试集,比例为8:1:1
模块化结构: 代码将整个流程模块化,使得代码更易于理解和维护。不同功能的代码块被组织成函数或者独立的模块,使…
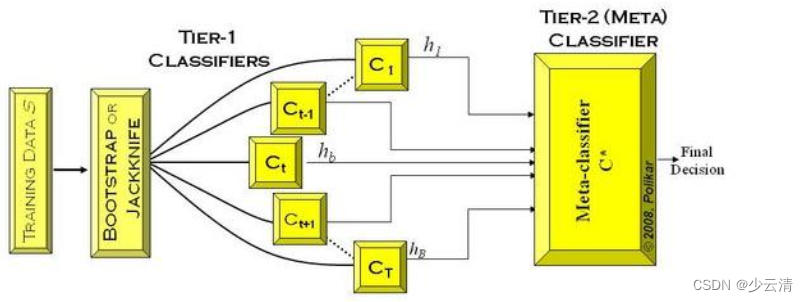
10_集成学习方法:随机森林、Boosting
文章目录 1 集成学习(Ensemble Learning)1.1 集成学习1.2 Why need Ensemble Learning?1.3 Bagging方法 2 随机森林(Random Forest)2.1 随机森林的优点2.2 随机森林算法案例2.3 随机森林的思考(--->提升学习) 3 随机森林(RF&a…

LESS模型与随机森林
模型学习
1 随机森林 https://blog.csdn.net/weixin_35770067/article/details/107346591? 森林就是建立了很多决策树,把很多决策树组合到一起就是森林。 这些决策树都是为了解决同一任务建立的,最终的目标也都是一致的,最后将其结果来平均…
集成学习算法随机森林发生过拟合时,如何调整超参数?
当随机森林算法发生过拟合时,可以通过调整以下超参数来解决问题:
1
n_estimators(树的数量):增加树的数量可以降低模型的过拟合程度。通过增加树的数量,可以减少每棵树对最终预测结果的影响,从…

sklearn随机森林 测试 路面点云分类
一、特征5个坐标 坐标-特征-类别 训练数据 二、模型训练
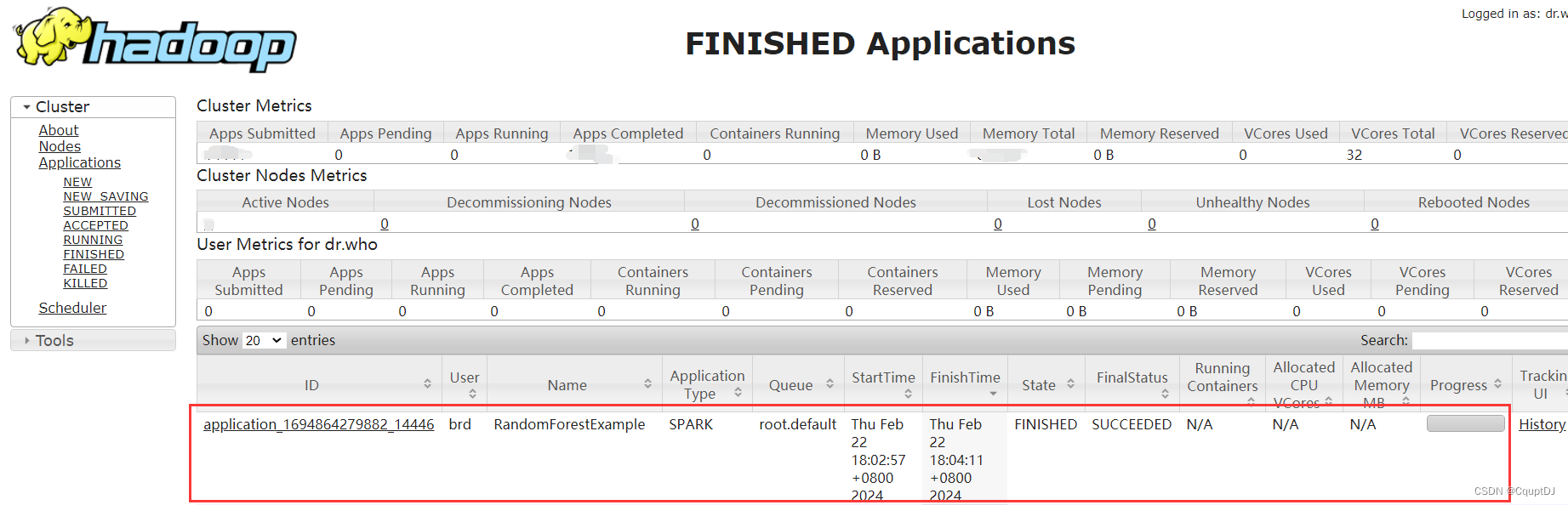
记录分享给有需要的人,代码质量勿喷
import numpy as np
import pandas as pd
import joblib#region 1 读取数据
dir D:\\py\\RandomForest\\
filename1 trainRS
filename2 .csv
path dirfilename1file…
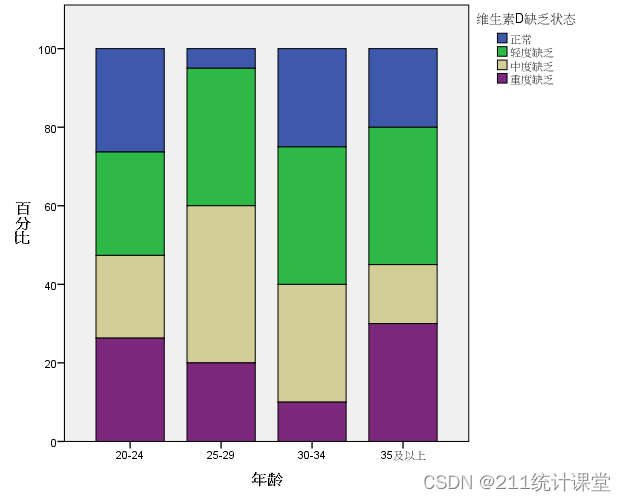
SPSS统计作图教程:百分条图堆积条图
1、问题与数据
某研究者想看不同年龄分组人群(Age_cat)中不同程度的维生素D缺乏(VD)的百分构成比,部分数据如图1。研究者想以条图形式来展现,该如何操作呢? 图1 部分数据
2. 具体操作…

Python用正则化Lasso、岭回归预测房价、随机森林交叉验证鸢尾花数据可视化2案例|数据分享...
全文链接:https://tecdat.cn/?p33632 机器学习模型的表现不佳通常是由于过度拟合或欠拟合引起的,我们将重点关注客户经常遇到的过拟合情况(点击文末“阅读原文”获取完整代码数据)。 相关视频 过度拟合是指学习的假设在训练数据上…

数据分享|SAS数据挖掘EM贷款违约预测分析:逐步Logistic逻辑回归、决策树、随机森林...
全文链接:http://tecdat.cn/?p31745 近几年来,各家商业银行陆续推出多种贷款业务,如何识别贷款违约因素已经成为各家商业银行健康有序发展贷款业务的关键(点击文末“阅读原文”获取完整数据)。 相关视频 在贷款违约预…
【MATLAB】使用随机森林在回归预测任务中进行特征选择(深度学习的数据集处理)
1.随机森林在神经网络的应用 当使用随机森林进行特征选择时,算法能够为每个特征提供一个重要性得分,从而帮助识别对目标变量预测最具影响力的特征。这有助于简化模型并提高其泛化能力,减少过拟合的风险,并且可以加快模型训练和推理…

全代码 | 随机森林在回归分析中的经典应用
公众号后台记录了发表过文章的各项阅读指标包括:内容标题,总阅读人数,总阅读次数,总分享人数,总分享次数,阅读后关注人数,送达阅读率,分享产生阅读次数,首次分享率&#…

【回归预测】基于DBO-RF(蜣螂优化算法优化随机森林)的回归预测 多输入单输出【Matlab代码#67】
文章目录 【可更换其他算法,获取资源请见文章第6节:资源获取】1. 随机森林RF算法2. 蜣螂优化算法3. 实验模型4. 部分代码展示5. 仿真结果展示6. 资源获取 【可更换其他算法,获取资源请见文章第6节:资源获取】 1. 随机森林RF算法
…
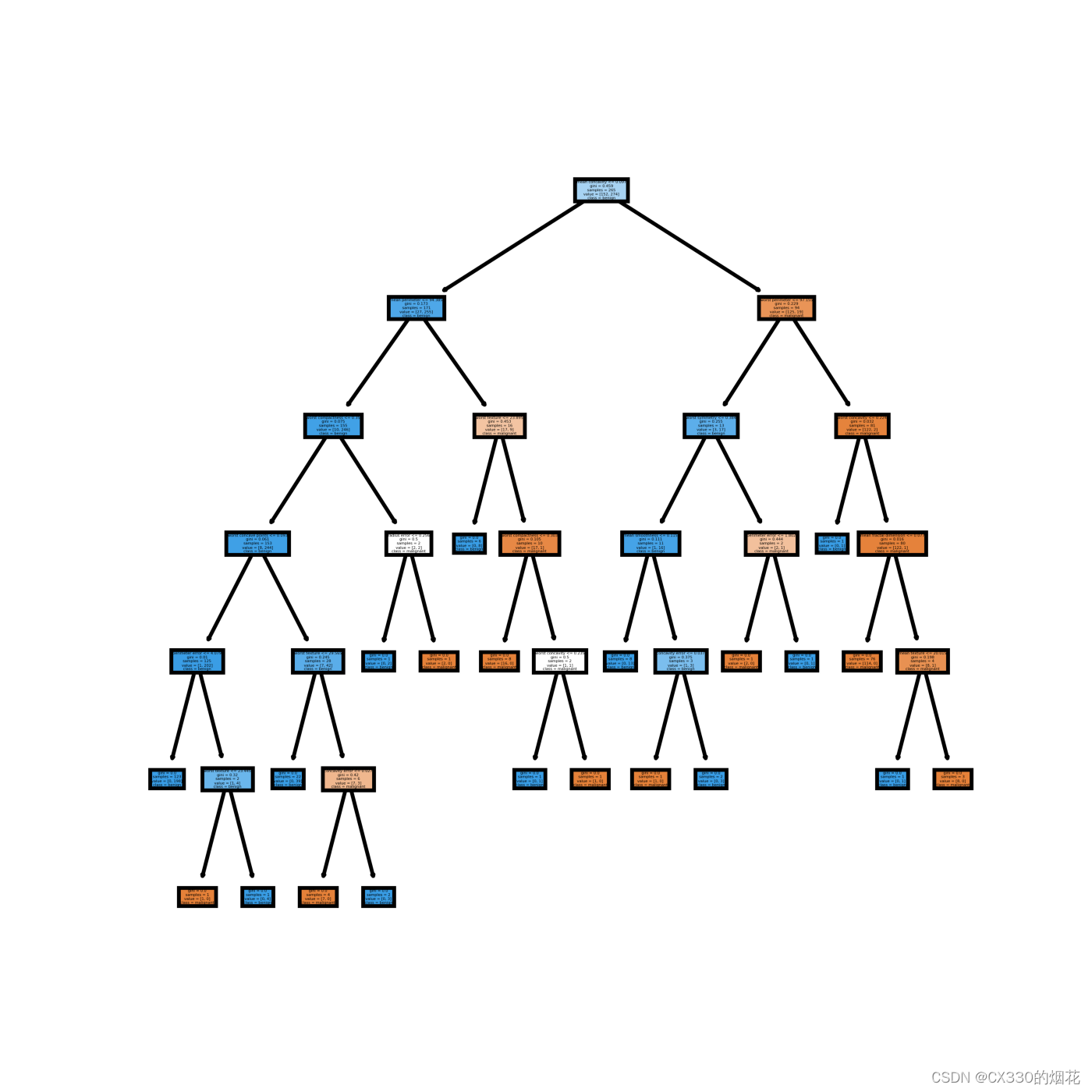
决策树算法优化(一篇文章 理解)
目录
引言
一、决策树的基本概念 二、决策树的构建过程
1 特征选择
2 决策树生成
3 决策树剪枝
三、决策树算法的缺点
1 过拟合问题
2 对噪声敏感
3 缺乏连续变量的处理
4 倾向于选择具有较多类别的特征
四、优化策略
1 集成学习
2 连续变量处理
3 特征选择优化 …

C2-4.3.1 多个决策树——随机森林
C2-4.3.1 多个决策树——随机森林
参考链接
1、为什么要使用多个决策树——随机森林?
决策树的缺点:
A small change in the data can cause a large change in the structure of the decision tree causing instability
即:对数据集 中…
数据分析系列 之python中随机森林算法的应用
1 原理 1.1 随机森林算法:随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,N棵树会有…
机器学习_10、集成学习-随机森林
随机森林算法
随机森林(Random Forest)是一种集成学习方法,特别用于分类、回归和其他任务,它通过构建多个决策树(Decision Trees)在训练时进行预测,并采用平均或多数投票的方式来提高整体模型的…

机器学习-面经(part6、集成学习)
10 集成学习 定义:通过结合多个学习器(例如同种算法但是参数不同,或者不同算法),一般会获得比任意单个学习器都要好的性能,尤其是在这些学习器都是"弱学习器"的时候提升效果会很明显。 10.1 Boosting(提升法) 可以用于回归和分类 问题,它每一…
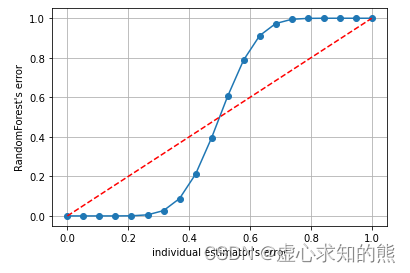
Lesson 9.4 随机森林在巨量数据上的增量学习和 Bagging 方法 6 大面试热点问题
文章目录一、随机森林在巨量数据上的增量学习1. 普通学习 vs 增量学习1.1 普通学习2. 增量学习2. 增量学习在 Kaggle 数据上的应用2.1 实际应用二、Bagging 方法 6 大面试热点问题Q1:为什么 Bagging 算法的效果比单个评估器更好?Q2:为什么 Ba…
Python基础小讲堂之条件分支与循环
万丈高楼平地起,今天给大家讲讲python中的:条件分支与循环。在学条件分支与循环之前,先掌握一下python的基本操作符。算术操作符: - * / % ** //对于算数操作符的前四个加减乘除,大家都懂,在py…
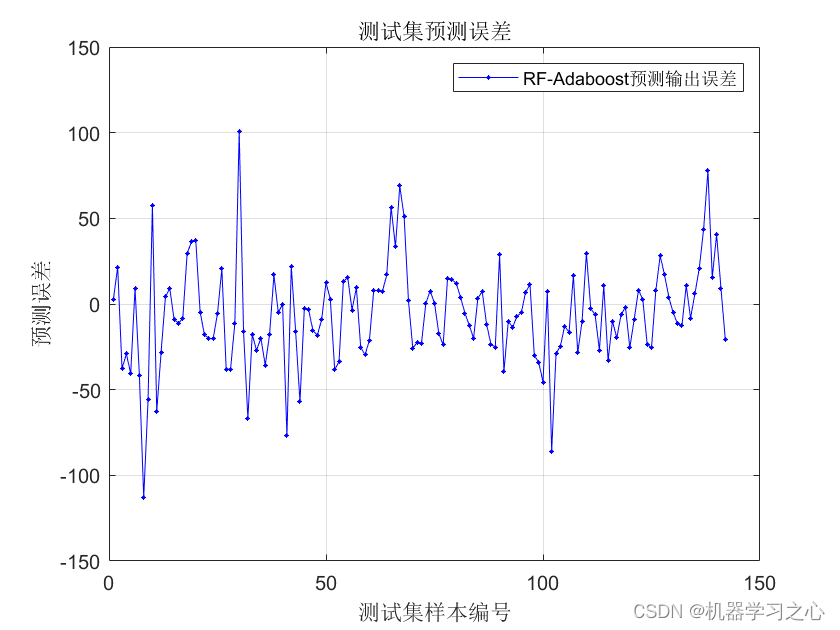
Adaboost集成学习 | Matlab实现基于RF-Adaboost随机森林结合Adaboost集成学习时间序列预测
目录 效果一览基本介绍模型设计程序设计参考资料效果一览 基本介绍 Matlab实现基于RF-Adaboost随机森林结合Adaboost集成学习时间序列预测。基于RF-Adaboost(随机森林结合Adaboost集成学习)的时间序列预测方法结合了随机森林在处理高维数据和复杂关系方面的优势,以及Adaboos…
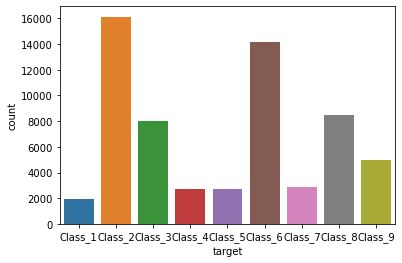
基于随机森林的otto商品分类
数据集介绍
Otto Group数据集来源于《Otto Group Product Classification Challenge》。Otto集团是世界上最大的电子商务公司之一,在20多个国家拥有子公司。我们每天在全球销售数百万种产品,在我们的产品线中添加了数千种产品。
我们公司对我们产品性能…
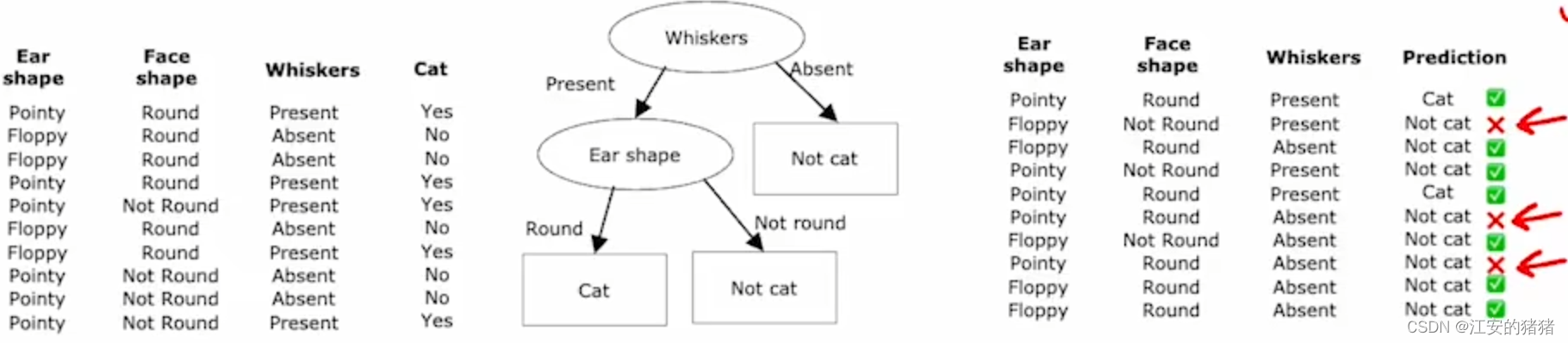
吴恩达deeplearning.ai:使用多个决策树随机森林
以下内容有任何不理解可以翻看我之前的博客哦:吴恩达deeplearning.ai专栏 文章目录 为什么要使用树集合使用多个决策树(Tree Ensemble)有放回抽样随机森林XGBoost(eXtream Gradient Boosting)XGBoost的库实现何时使用决策树决策树和树集合神经网络 使用单个决策树的…
sklearn随机森林实现(备忘版)
scikit-learn是广泛使用的机器学习python库. sklearn已经实现了决策树及集成模型, 下面是随机森林分类算法实现的示例代码.
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
datasetpd.read_table(/path/to/DataSet/Classificat…
机器学习总结一:Bagging之决策树、随机森林原理与案例
机器学习算法总结
一、Bagging之决策树、随机森林原理与案例
二、boosting之GBDT、XGBT原理推导与案例
三、SVM原理推导与案例
四、逻辑回归与反欺诈检测案例
五、聚类之K-means 一、Bagging之决策树、随机森林原理与案例
1. 决策树
1.1 简介
决策树(Decision Tree)是一…
机器学习 | MATLAB实现RF随机森林模型答疑(适应度函数)
机器学习 | MATLAB实现RF随机森林模型答疑(适应度函数) 目录 机器学习 | MATLAB实现RF随机森林模型答疑(适应度函数)基本介绍答疑一答疑二答疑三答疑四答疑五基本介绍 机器学习 | MATLAB实现RF随机森林模型答疑(适应度函数)及贝叶斯优化 答疑一 遗传算法(Genetic Algori…

年终好价节买什么好?这些数码好物闭眼入
大家是不是都没听说过好价节?直截了当地说,这其实就是原先的双十二购物狂欢节,只不过给它起了个新名字。不过,今年毕竟是首次改名,因此淘宝年终好价节的各种优惠,仍然是我们值得期待的!作为年前…

机器学习笔记 十五:随机森林(Random Forest)评估机器学习模型的特征重要性
随机森林1. 随机森林介绍1.1 租赁数据案例2. 特征相关性分析(热图)2.1 热图绘制2.2 构建随机森林模型2.3 不同特征合并的重要性2.3.1 经纬度合并(分3类)2.3.2 经纬度合并(分2类)2.3.3 经纬度合并࿰…
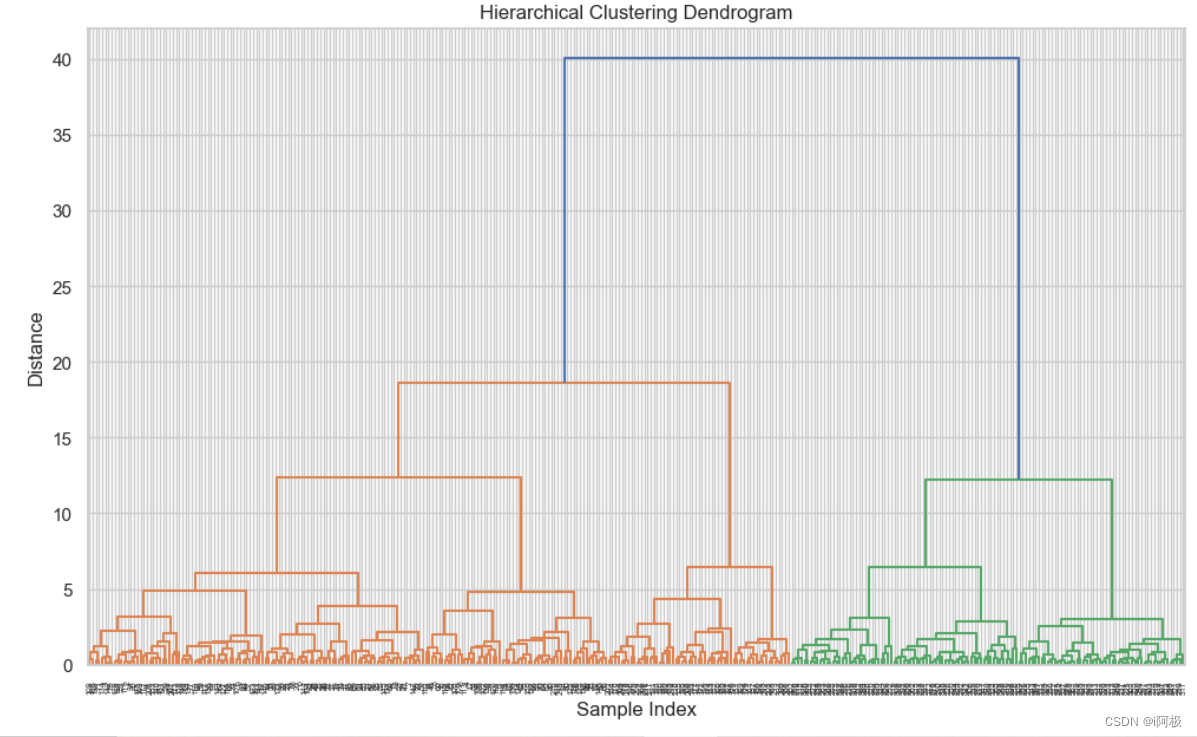
基于决策树、随机森林和层次聚类对帕尔默企鹅数据分析
作者:i阿极 作者简介:数据分析领域优质创作者、多项比赛获奖者:博主个人首页 😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒关注哦&#x…
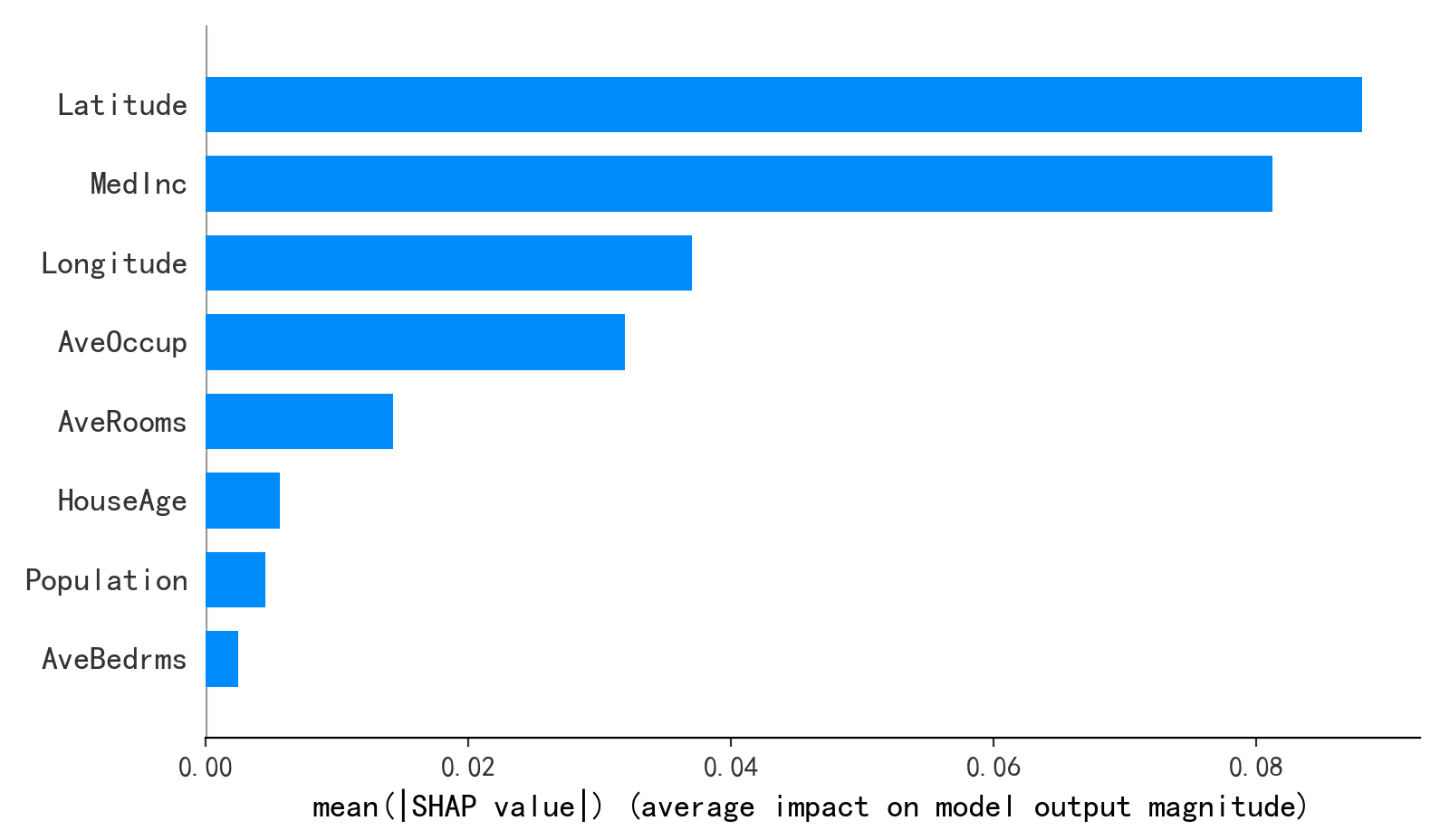
数据分析 | 特征重要性分析 | 树模型、SHAP值法
前言 在分析特征重要性的时候,相关性分析和主成分分析往往是比较简单的方法,相关性分析是通过计算特征与目标变量之间的相关系数来评估特征的重要性。它可以告诉我们特征和目标变量之间的线性关系程度,但对于非线性关系就无能为力了ÿ…

GEE:面对对象(斑块/超像素)尺度的随机森林回归教程
作者:CSDN @ _养乐多_
本文将介绍在Google Earth Engine(GEE)平台上进行面向对象随机森林回归的方法和代码。
在使用遥感数据进行回归预测中,以往的回归方法大多基于像素,然而,基于像素的回归通常忽略了相邻像素之间的关系,因此可能无法捕捉到空间上的一致性信息;相邻…
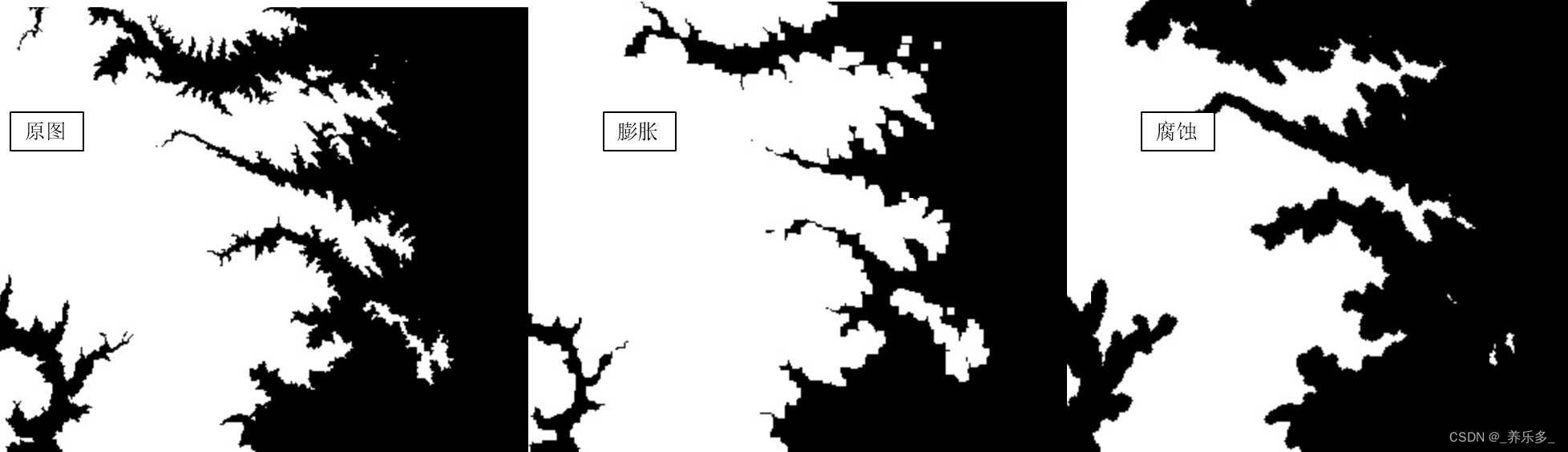
GEE:为机器学习算法(随机森林、支持矢量机等)加入膨胀/腐蚀特征
作者:CSDN @ _养乐多_
腐蚀和膨胀 是数学形态学图像处理中的两个基本操作,用于修改和分析二值图像(包含只有两个像素值的图像,通常是黑和白)。这些操作可用于博客《GEE:随机森林分类教程(样本制作、特征添加、训练、精度、参数优化、贡献度、统计面积)》中写的机器学习…
【机器学习300问】35、什么是随机森林?
〇、让我们准备一些训练数据
idx0x1x2x3x4y04.34.94.14.75.5013.96.15.95.55.9022.74.84.15.05.6036.64.44.53.95.9146.52.94.74.66.1152.76.74.25.34.81 表格中的x0到x4一共有5个特征,y是目标值只有0,1两个值说明是一个二分类问题。 关于决策树相关的前置知识&am…
如何使用R语言模拟物种气候生态位动态量化与分布特征
R语言
R是统计领域广泛使用的诞生于1980年左右的S语言的一个分支。可以认为R是S语言的一种实现。而S语言是由AT&T贝尔实验室开发的一种用来进行数据探索、统计分析和作图的解释型语言。最初S语言的实现版本主要是S-PLUS。S-PLUS是一个商业软件,它基于S语言&…

回归预测 | MATLAB实现PSO-RF粒子群算法优化随机森林多输入单输出回归预测
回归预测 | MATLAB实现PSO-RF粒子群算法优化随机森林多输入单输出回归预测 目录回归预测 | MATLAB实现PSO-RF粒子群算法优化随机森林多输入单输出回归预测效果一览基本介绍程序设计参考资料效果一览 基本介绍 MATLAB实现PSO-RF粒子群算法优化随机森林多输入单输出回归预测 粒子…
![[Python] 什么是集成算法,什么是随机森林?随机森林分类器(RandomForestClassifier)及其使用案例](https://img-blog.csdnimg.cn/direct/b862784f6a9b48c5b0276a8e903eb596.png)
[Python] 什么是集成算法,什么是随机森林?随机森林分类器(RandomForestClassifier)及其使用案例
什么是集成算法?
集成算法是一种机器学习方法,它将多个基本的学习算法(也称为弱学习器)组合在一起,形成一个更强大的预测模型。集成算法通过对基本模型的预测进行加权平均或多数投票等方式,来产生最终的预…

数据分享|R语言逻辑回归、线性判别分析LDA、GAM、MARS、KNN、QDA、决策树、随机森林、SVM分类葡萄酒交叉验证ROC...
全文链接:http://tecdat.cn/?p27384 在本文中,数据包含有关葡萄牙“Vinho Verde”葡萄酒的信息(点击文末“阅读原文”获取完整代码数据)。 介绍 该数据集(查看文末了解数据获取方式)有1599个观测值和12个变量…
故障诊断模型 | Maltab实现RF随机森林的故障诊断
效果一览 文章概述 故障诊断模型 | Maltab实现RF随机森林的故障诊断 模型描述
RF善于处理高维数据,特征遗失数据,和不平衡数据
(1)训练可以并行化,速度快
(2)对高维数据集的处理能力强,它可以处理成千上万的输入变量,并确定最重要的变量,因此被认为是一个不错的降…

基于机器学习的信用卡办卡意愿模型预测项目
基于机器学习的信用卡办卡意愿模型预测项目
在金融领域,了解客户的信用卡办卡意愿对于银行和金融机构至关重要。借助机器学习技术,我们可以根据客户的历史数据和行为模式预测其是否有办理信用卡的倾向。本项目通过Python中的机器学习库,构建…
Bagging的随机森林;Boosting的AdaBoost和GBDT
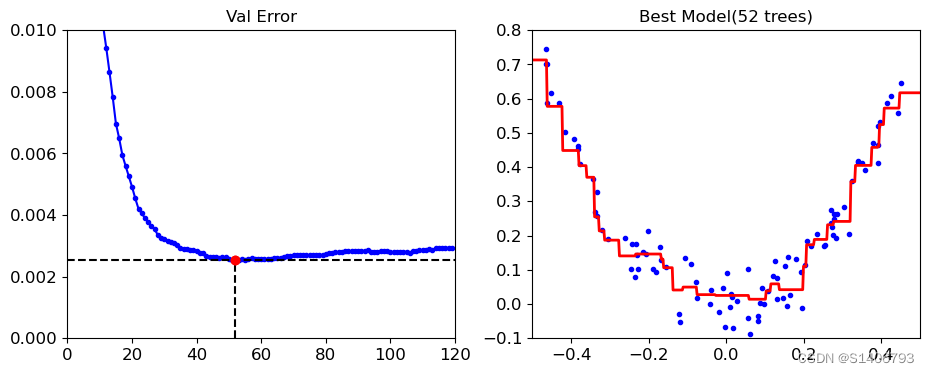
集成学习应用实践
import numpy as np
import os
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams[axes.labelsize] 14
plt.rcParams[xtick.labelsize] 12
plt.rcParams[ytick.labelsize] 12
import warnings
warnings.filterwarnin…

sklearn机器学习库(二)sklearn中的随机森林
sklearn机器学习库(二)sklearn中的随机森林
集成算法会考虑多个评估器的建模结果,汇总之后得到一个综合的结果,以此来获取比单个模型更好的回归或分类表现。
多个模型集成成为的模型叫做集成评估器(ensemble estimator)…
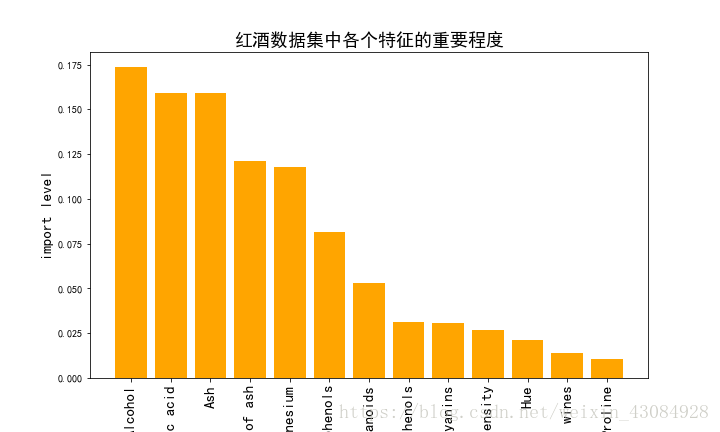
利用随机森林进行特征选择
例子是wine数据集: http://archive.ics.uci.edu/ml/machine-learning-databases/wine/ 之所以可以利用随即森立来进行特征筛选是由于决策树的特性,因此我们可以利用所有决策树得到的平均不纯度(基尼系数)衰减来量化特征的重要性。…

解密人工智能:决策树 | 随机森林 | 朴素贝叶斯
文章目录 一、机器学习算法简介1.1 机器学习算法包含的两个步骤1.2 机器学习算法的分类 二、决策树2.1 优点2.2 缺点 三、随机森林四、Naive Bayes(朴素贝叶斯)五、结语 一、机器学习算法简介
机器学习算法是一种基于数据和经验的算法,通过对…
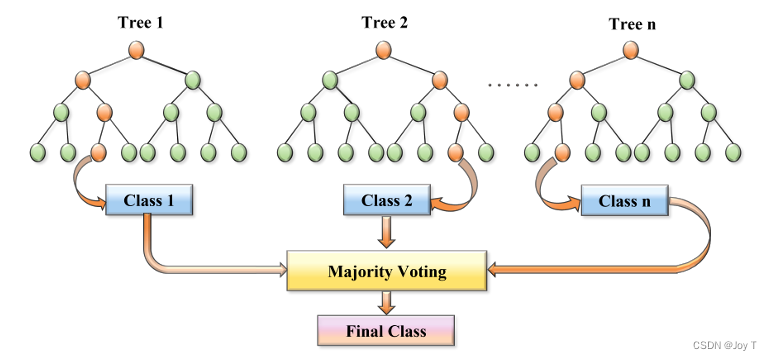
一文理解什么是贝叶斯优化的随机森林
贝叶斯优化
简介 贝叶斯优化是一种启发式的全局优化方法,用于优化那些评估代价高昂且可能带有噪音的黑盒函数。其核心思想是:在每一步,都利用已知的函数评估来构建一个概率模型,预测黑盒函数在未知点上的值,并据此选择…
深入理解数据结构森林
文章目录 一、森林是什么二、森林的应用范围三、森林结构的MQL语言实现 一、森林是什么 数据结构中的"森林"是指多个树的集合。在树的概念中,每个节点可以有多个子节点,而在森林中,每个树都是独立的,没有共享的节点。换…
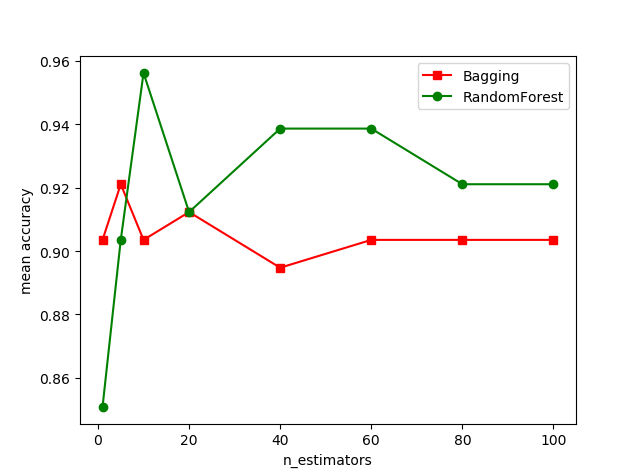
随机森林(random forest)
随机森林(random forest)写在前面:本博客为周志华《机器学习》随机森林部分的读书笔记,虽有自己微小的理解补充,但理论部分大部分内容依然来自西瓜书。
集成学习系列博客:
集成学习(ensemble …

随机森林RF介绍与使用(实操)
随机森林(RF) RF算法流程
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import matplotlib.pyplot as plt# 载入数据
data np.genfrom…

【监督学习之决策树和随机森林】
曾梦想执剑走天涯,我是程序猿【AK】 目录 简述概要知识图谱决策树(Decision Tree)随机森林(Random Forest) 简述概要
了解决策树和随机森林
知识图谱
决策树和随机森林都是机器学习中常用的算法,它们在处…

四、分类算法 - 随机森林
目录
1、集成学习方法
2、随机森林
3、随机森林原理
4、API
5、总结 sklearn转换器和估算器KNN算法模型选择和调优朴素贝叶斯算法决策树随机森林
1、集成学习方法 2、随机森林 3、随机森林原理 4、API 5、总结

时序预测 | MATLAB实现基于RF随机森林的时间序列预测-递归预测未来(多指标评价)
时序预测 | MATLAB实现基于RF随机森林的时间序列预测-递归预测未来(多指标评价) 目录 时序预测 | MATLAB实现基于RF随机森林的时间序列预测-递归预测未来(多指标评价)预测结果基本介绍程序设计参考资料 预测结果 基本介绍 MATLAB实现基于RF随机森林的时间序列预测-递归预测未来…
随机森林回归模型,SHAP库可视化
随机森林回归模型
创建一个随机森林回归模型,训练模型,然后使用SHAP库解释模型的预测结果,并将结果可视化。
具体步骤如下: 首先,代码导入了所需的库,包括matplotlib、shap、numpy和sklearn.ensemble。ma…
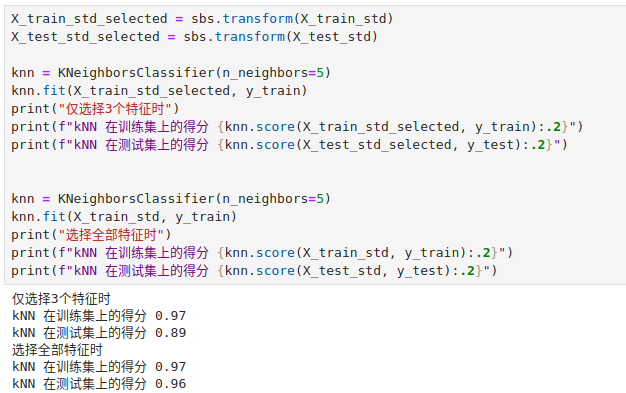
机器学习系列13:通过随机森林获取特征重要性
我们已经知道通过 L1 正则化和 SBS 算法可以用来做特征选择。
我们还可以通过随机森林从数据集中选择相关的特征。随机森林里面包含了多棵决策树,我们可以通过计算特征在每棵决策树决策过程中所产生的的信息增益平均值来衡量该特征的重要性。
你可能需要参考&…
多维时序 | Matlab实现RF-Adaboost随机森林结合Adaboost多变量时间序列预测
多维时序 | Matlab实现RF-Adaboost随机森林结合Adaboost多变量时间序列预测 目录 多维时序 | Matlab实现RF-Adaboost随机森林结合Adaboost多变量时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.Matlab实现RF-Adaboost随机森林结合Adaboost多变量时间序列预…
GEE 23:基于GEE实现物种分布模型之随机森林算法(Random Forest)
物种分布模型之随机森林法 1.物种分布数据2.研究区绘制3.预测因子选择4.多重共线性分析5.伪不存在点生成6.验证数据准备(重复分割块样本交叉验证)7.模型拟合、验证和预测8.提取及展示模型预测结果9.精度评估10.结果导出11.常见函数解释1.物种分布数据 根据研究目的和需要导入…

机器学习 随机森林与集成模型 2022-01-10
人工智能基础总目录 随机森林-集成学习一、随机森林二、Ensemble learning三、boostingAdaptive boosting(可调节的)Gradient BoostingXgboost 和 LightBGM四、 代码实践4.1 决策树4.2 随机森林4.3 GBDT4.4 Bagging4.5 Boosting集成模型一、随机森林
决…
【GA-ACO-RFR预测】基于混合遗传算法-蚁群算法优化随机森林回归预测研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…
决策树和随机森林算法 简介
决策树(Decision Tree) 是一种基础的分类和回归算法随机森林 是由多棵决策树集成在一起的集成学习算法
决策树生成过程:
特征选择决策树生成决策树剪枝
信息熵
用来衡量一个节点内信息的不确定性的。
信息熵越大, 不确定性越大, 样本就越多样, 样本…
随笔:集成学习:关于随机森林,梯度提升机的东拉西扯
1.集成学习
这里不会描述算法过程。
当我们有许多学习器对同一个任务做出判断,他们预测的概率可能各不相同,比如预测一个男生(小徐)会不会喜欢另一个女生(小雪),支持向量机算出来小徐爱上小雪的概率是0.8,朴素贝叶斯认为是0.3&a…

分类预测 | Matlab实现GA-RF遗传算法优化随机森林多输入分类预测
分类预测 | Matlab实现GA-RF遗传算法优化随机森林多输入分类预测 目录 分类预测 | Matlab实现GA-RF遗传算法优化随机森林多输入分类预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 Matlab实现GA-RF遗传算法优化随机森林多输入分类预测(完整源码和数据&…

1、中级机器学习课程简介
文章目录 1、课程简介2、先决条件 本课程所需数据集夸克网盘下载链接:https://pan.quark.cn/s/9b4e9a1246b2 提取码:uDzP 1、课程简介
欢迎来到机器学习中级课程!
如果你对机器学习有一些基础,并且希望学习如何快速提高模型质量…

科室推荐实践(随机森林模型)
数据:性别 年龄 症状(实体抽取模型抽取对主诉抽取出症状) 科室
1.训练词向量(对症状去重,生成字典,使用pkuseg.pktest()分词并指定词典) 2.将对应症状转换为词向量,加上性别&#x…
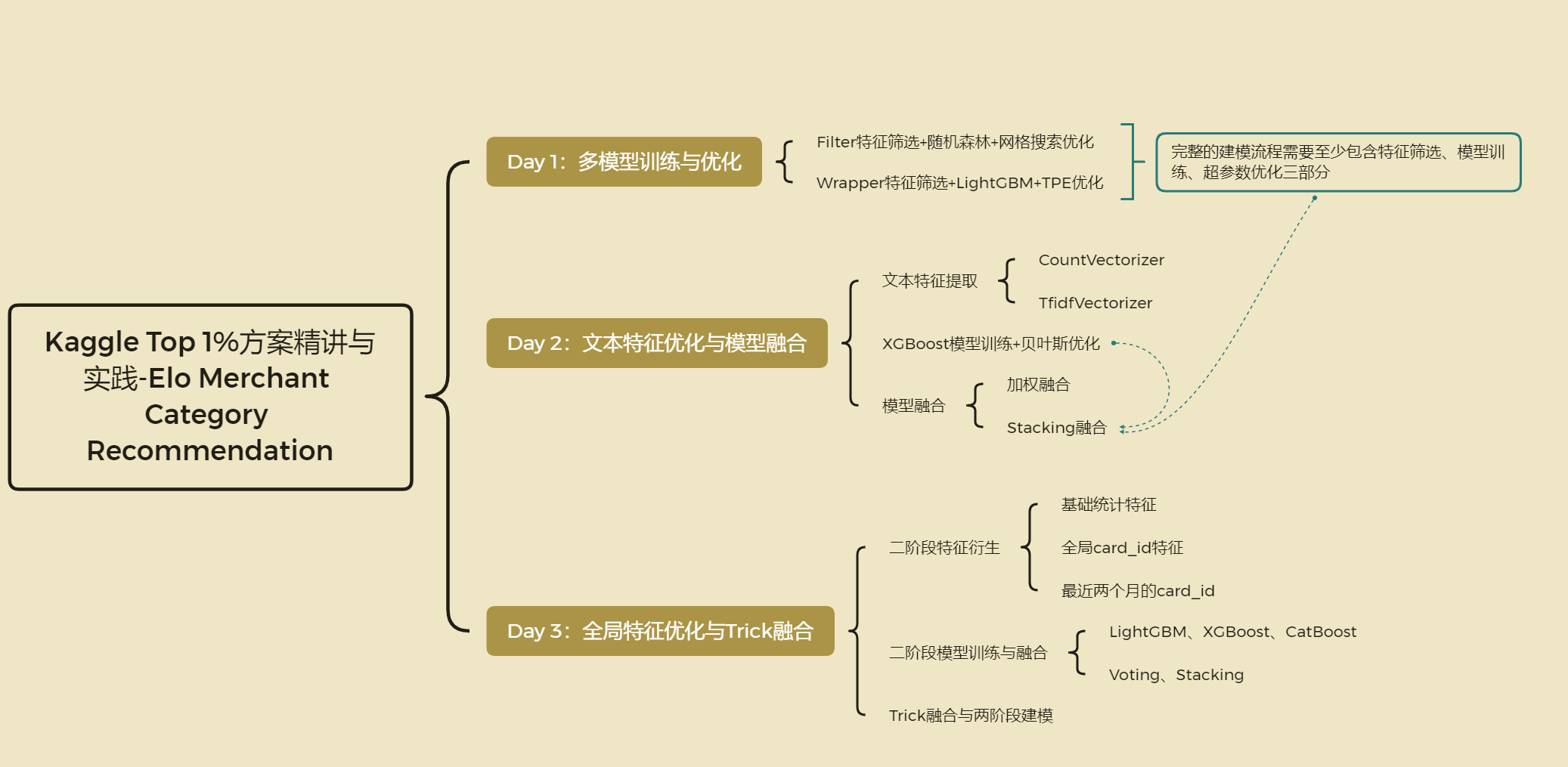
Filter特征筛选+随机森林建模+网格搜索调优(Kaggle--Elo Merchant Category Recommendation)
数据预处理流程 思路 import pandas as pd
import numpy as np数据读取
train pd.read_csv("preprocess/train.csv")
test pd.read_csv("preprocess/test.csv")随机森林模型预测
特征选择–皮尔逊相关系数
(train.shape, test.shape)((201917, 1700),…
Filter特征筛选+随机森林建模+交叉验证(kaggle-Elo Merchant Category Recommendation)
数据预处理流程 思路 数据读取
import pandas as pd
import numpy as np
from sklearn.model_selection import KFold
from numpy.random import RandomState
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_errortrain pd.r…

机器学习——决策树/随机森林
0、前言:
决策树可以做分类也可以做回归,决策树容易过拟合决策树算法的基本原理是依据信息学熵的概念设计的(Logistic回归和贝叶斯是基于概率论),熵最早起源于物理学,在信息学当中表示不确定性的度量&…
【PSO-RFR预测】基于粒子群算法优化随机森林回归预测研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…

【基于CART的随机森林学习笔记】
目录算法描述知识储备举个栗子实现代码算法分析资料引用算法描述
1.随机森林是指一片森林的每棵树都表决,进而根据少数服从多数的原则决断出最后的结果。此篇以CART作为每一棵树的基本模型来说明。 2.算法过程: ①Bootstrap sample构造数据集。 ②为每个…
基于随机森林算法的房价模型预测研究
基于随机森林算法的房价模型预测研究
摘要:本研究利用波士顿郊区房价的信息,并构建了全面的数据集。采用随机森林算法构建了房价预测模型,通过构建模型,并使用Grid Search进行超参数调整及交叉验证对模型进行优化,提高该模型房地产市场的房价预测准确性。研究对象为波士顿…
机器学习系列--R语言随机森林进行生存分析(1)
随机森林(Breiman 2001a)(RF)是一种非参数统计方法,需要没有关于响应的协变关系的分布假设。RF是一种强大的、非线性的技术,通过拟合一组树来稳定预测精度模型估计。随机生存森林(RSF࿰…

机器学习算法基础学习 # 集成学习之随机森林
随机森林(Random Forests) 是集成学习算法的一种。集成学习是通过组合多个学习器来完成学习任务。随机森林是结合多颗决策树来对样本进行训练和预测。随机森林通过随机扰动而令所有的树去相关。 随机森林可以使用巨量的预测器,甚至预测器的数量比观察样本的数量还多…
集成学习:Bagging, Boosting,Stacking
目录
集成学习
一、bagging
二、boosting
Bagging VS Boosting
1.1 集成学习是什么?
Bagging
Boosting
Stacking
总结 集成学习
好比人做出一个决策时,会从不同方面,不同角度,不同层次去思考(多个自我&am…
机器学习十大算法之七——随机森林
0 引言
集成学习(ensemble learning)是时下非常流行的机器学习算法,它本身不是一个单独的机器学习算法,而是通过在数据上构建多个横型,集成所有模型的建模结果,基本上所有的机器学习领域都可以看到集成学习…
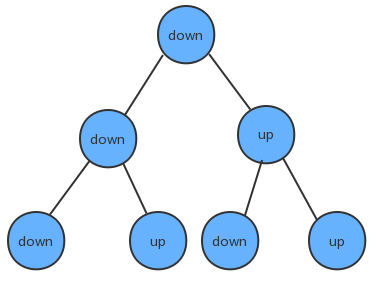
数据结构与算法(六)树的入门
树的基本定义
树是我们计算机中非常重要的一种数据结构,同时使用树这种数据结构,可以描述现实生活中的很多事物,例如家谱、单位的组织架构、等等。 树是由n(n>1)个有限结点组成一个具有层次关系的集合。把它叫做“…

【回归预测】基于SSA-RF(麻雀搜索算法优化随机森林)的回归预测 多输入单输出【Matlab代码#66】
文章目录 【可更换其他算法,获取资源请见文章第6节:资源获取】1. 随机森林RF算法2. 麻雀搜索算法3. 实验模型4. 部分代码展示5. 仿真结果展示6. 资源获取 【可更换其他算法,获取资源请见文章第6节:资源获取】 1. 随机森林RF算法
…
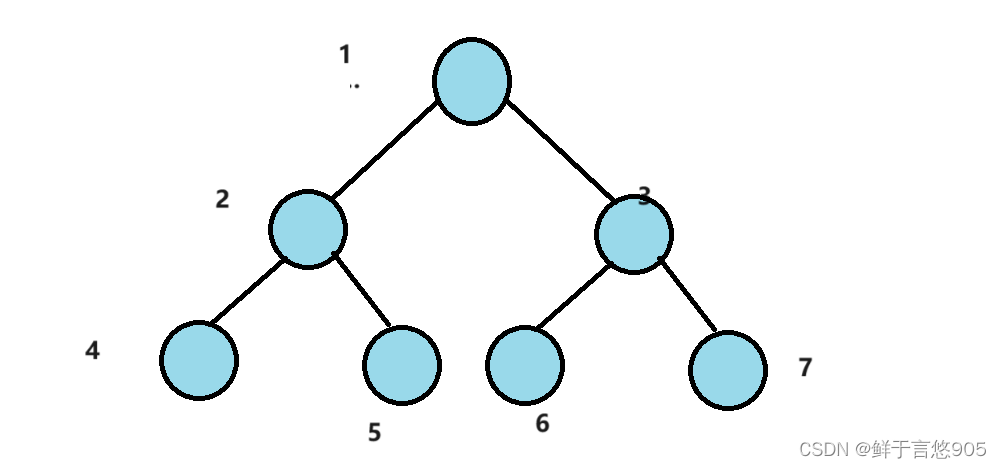
数据结构从入门到精通——树和二叉树
树和二叉树 前言一、树概念及结构1.1树的概念1.2 树的相关概念(重要)1.3 树的表示1.4 树在实际中的运用(表示文件系统的目录树结构) 二、二叉树概念及结构2.1二叉树概念2.2现实中的二叉树2.3 特殊的二叉树2.4 二叉树的性质2.5 二叉…

【量化交易笔记】7.基于随机森林预测股票价格
前言
机器学习在量化交易主要有两方面的应用,第一就是用时间序列的日频数据来预测未来的股价,第二 用截面数据来预测收益,现在量化基因的因子都基于这个模型。 接下来,我分别来说明,机器学习分成预测结果分成分类和回…
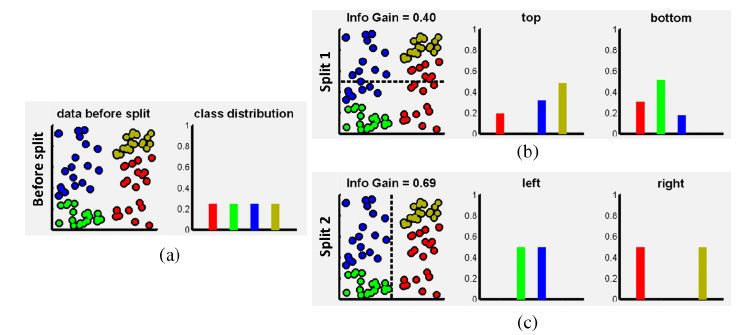
importance中信息增益和基尼系数
1.信息增益和基尼系数的异同点
信息增益和基尼系数都是用于评价决策树分裂节点的指标,它们有以下主要的相同点和不同点:
相同点:
都用于测度数据集的无序程度(impurity),可以评价分裂后的无序程度减少量取值范围都在0到1之间,0表示完全有序都遵循同一思路,优先选择造成无序程…
随机森林算法原理及应用方法
一、基本原理 1.随机森林由多棵决策树组成,可用于分类,回归和其他任务集成学习方法。 是一种有监督学习算法,目的是降低方差,相比决策树能避免模型太大时过拟合,会小幅增加偏差和损失部分可解释性为代价, 准…
MATLAB环境下基于决策树和随机森林的心力衰竭患者生存情况预测
近年来,随着医学数据的不断积累和计算机技术的快速发展,许多机器学习技术已经被用在医学领域,并取得了不错的效果。与传统的基于医学知识经验的心衰预后评估模型相比,机器学习方法可以快速、高效地从繁杂的、海量的心衰病人数据中…
机器学习(5):提升算法(boosting algorithm)
最近自己会把自己个人博客中的文章陆陆续续的复制到CSDN上来,欢迎大家关注我的 个人博客,以及我的github。
本文将讲解有关提升算法的知识,主要包括提升算法的基本思想,以及几个具体的提升算法——AdaBoost算法、梯度提升决策树。…
基于天鹰算法优化随机森林RF的分类预测,AO-RF分类预测
目录 背影 摘要 随机森林的基本定义 随机森林实现的步骤 天鹰算法原理 基于天鹰算法优化随机森林的分类预测 完整代码下载链接: 基于天鹰算法改进的RF多分类代码,粒子群算法改进RF多分类代码,RB多分类代码,BP神经网络多分类代码资源-CSDN文库 https://download.csdn.net/do…
机器学习 | 基于随机森林的可解释性机器学习
可解释性机器学习在当今数据驱动的决策系统中扮演着重要的角色。随着人工智能技术的快速发展,越来越多的应用场景需要了解和解释模型的决策过程,以提高透明度、可信度和可接受性。乳腺癌作为一种常见的恶性肿瘤,早期诊断对于治疗和预后具有重要意义。
然而,乳腺癌早期诊断…
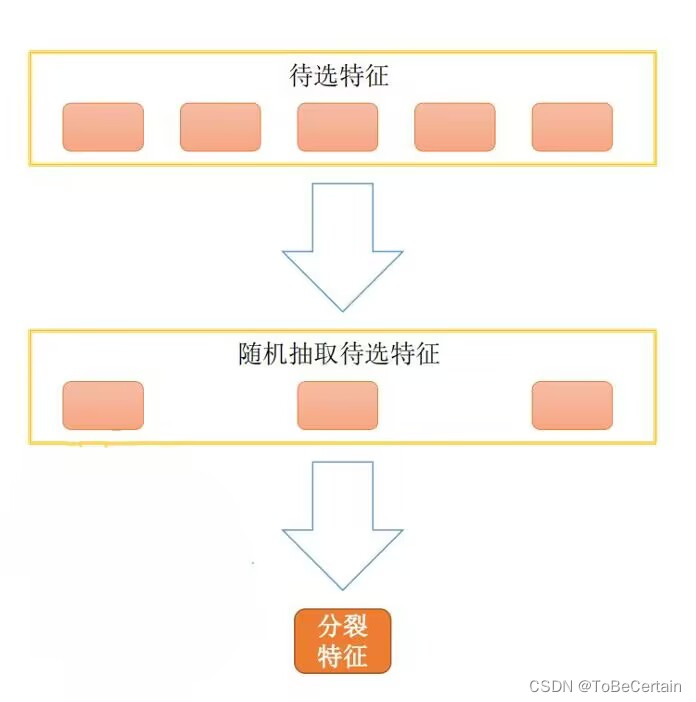
集成学习 | 集成学习思想:Bagging思想
目录 一. Bagging思想1. Bagging 算法2. 随机森林(Random Forest)算法 在正文开始之前,我们先来聊一聊什么是集成学习? 集成学习是一种算法思想:将若干个弱学习器分组之后,产生一个新的学习器 弱学习器指预测误差在50%以下的学习器…

机器学习 day38(有放回抽样、随机森林算法)
有放回抽样
有放回抽样和无放回抽样的区别:有放回可以确保每轮抽取的结果不一定相同,无放回则每轮抽取的结果都相同 在猫狗的例子中,我们使用”有放回抽样“来抽取10个样本,并组合为一个与原始数据集不同的新数据集,虽…
随机森林模型、模型模拟技术和决策树模型简介
随机森林模型、模型模拟技术和决策树模型简介
随机森林模型
随机森林模型是一种比较新的机器学习模型,它是通过集成学习的方法将多个决策树模型组合起来,形成一个更加强大和稳定的模型。随机森林模型的基本原理是“数据随机”和“特征随机”࿰…
17. 机器学习 - 随机森林
Hi,你好。我是茶桁。
我们之前那一节课讲了决策树,说了决策树的优点,也说了其缺点。
决策树实现起来比较简单,解释解释性也比较强。但是它唯一的问题就是不能拟合比较复杂的关系。
后来人们为了解决这个问题,让其能…
机器学习实战3-随机森林算法
文章目录 集成算法概述sklearn中的集成算法模块 RandomForestClassifier重要参数&&随机森林的分类器控制基评估器的参数n_estimatorssklearn建模流程复习交叉验证我们进行10次交叉验证,观察随机森林和决策树的效果n_estimators学习曲线 bootstrap & oob…

机器学习系列——(十五)随机森林回归
引言
在机器学习的众多算法中,随机森林以其出色的准确率、对高维数据的处理能力以及对训练数据集的异常值的鲁棒性而广受欢迎。它是一种集成学习方法,通过构建多个决策树来进行预测和分类。本文将重点介绍随机森林在回归问题中的应用,即随机…

回归预测 | MATLAB实现GA-RF遗传算法优化随机森林算法多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现GA-RF遗传算法优化随机森林算法多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现GA-RF遗传算法优化随机森林算法多输入单输出回归预测(多指标,多图)效果一览基本介绍程…

数据分析 | 随机森林如何确定参数空间的搜索范围
1. 随机森林超参数 极其重要的三个超参数是必须要调整的,一般再加上两到三个其他超参数进行优化即可。 2. 学习曲线确定n_estimators搜索范围 首先导入必要的库,使用sklearn自带的房价预测数据集:
import numpy as np
import pandas as pd
f…
pyspark分布式部署随机森林算法
前言
分布式算法的文章我早就想写了,但是一直比较忙,没有写,最近一个项目又用到了,就记录一下运用Spark部署机器学习分类算法-随机森林的记录过程,写了一个demo。
基于pyspark的随机森林算法预测客户
本次实验采用的…
机器学习_PySpark-3.0.3随机森林回归(RandomForestRegressor)实例
机器学习_PySpark-3.0.3随机森林回归(RandomForestRegressor)实例
随机森林回归 (Random Forest Regression):
任务类型: 随机森林回归主要用于回归任务。在回归任务中, 算法试图预测一个连续的数值输出, 而不是一个离散的类别。
输出: 随机森林回归的输出是一个连续的数值,…
基于Spark中随机森林模型的天气预测系统
基于Spark中随机森林模型的天气预测系统
在这篇文章中,我们将探讨如何使用Apache Spark和随机森林算法来构建一个天气预测系统。该系统将利用历史天气数据,通过机器学习模型预测未来的天气情况,特别是针对是否下雨的二元分类问题。
简介 Ap…

ArcGISPro随机森林自动化调参分类预测模型展示
更改ArcGISPro的python环境变量请参考文章
ArcGISPro中如何使用机器学习脚本_Z_W_H_的博客-CSDN博客
脚本文件如下 点击运行 结果展示
负类预测概率 正类预测概率 二值化概率 文件夹(模型验证结果)
数据集数据库 ROC曲线
由于个人数据量太少所以…
python:评估分类模型性能的常用指标(acc、auc、roc)
本文记录了评估分类模型性能的常用指标ACC、AUC、ROC曲线的计算方法和代码。代码使用python实现。
简介
ACC(Accuracy)是模型的准确率,即模型正确预测的样本数占总样本数的比例。ACC 可以用来评估模型在整体上的分类效果,但它不能很好地反映模型在不同类别上的表现差异。…
大数据分析案例-基于随机森林算法构建二手房价格预测模型
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…
GPT如何与回归模型分析、混合效应模型、多元统计分析及结构方程模型、Meta分析、随机森林模型及贝叶斯回归分析结合应用
自2022年GPT(Generative Pre-trained Transformer)大语言模型的发布以来,它以其卓越的自然语言处理能力和广泛的应用潜力,在学术界和工业界掀起了一场革命。在短短一年多的时间里,GPT已经在多个领域展现出其独特的价值…
随机森林原理sklearn实现
原理
定义 随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树, 而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。 随机森林的名称中有两个关键词,一个是“随机”&a…

集成学习以及随机森林介绍
一、集成学习简介
1.什么是集成学习?
集成学习(Ensemble Learning)是一种机器学习方法,通过将多个弱学习器(weak learner)组合在一起来构建一个更强大的学习器(strong learner)。 …

8分SCI | 揭示随机森林的解释奥秘:探讨LIME技术如何提高模型的可解释性与可信度!
一、引言 Local Interpretable Model-agnostic Explanations (LIME) 技术作为一种局部可解释性方法,能够解释机器学习模型的预测结果,并提供针对单个样本的解释。通过生成局部线性模型来近似原始模型的预测,LIME技术可以帮助用户理解模型在特…

基于Ray的分布式版本的决策树与随机森林
微信公众号:大数据高性能计算 在金融场景或者其余场景,经常我们需要进行规则或者是策略,如何通过一些算法对入模特征完成分布式化的规则切分是必须要做的事情。这里面有两个点:一种是规则切分成可解释性的规则,天然比…
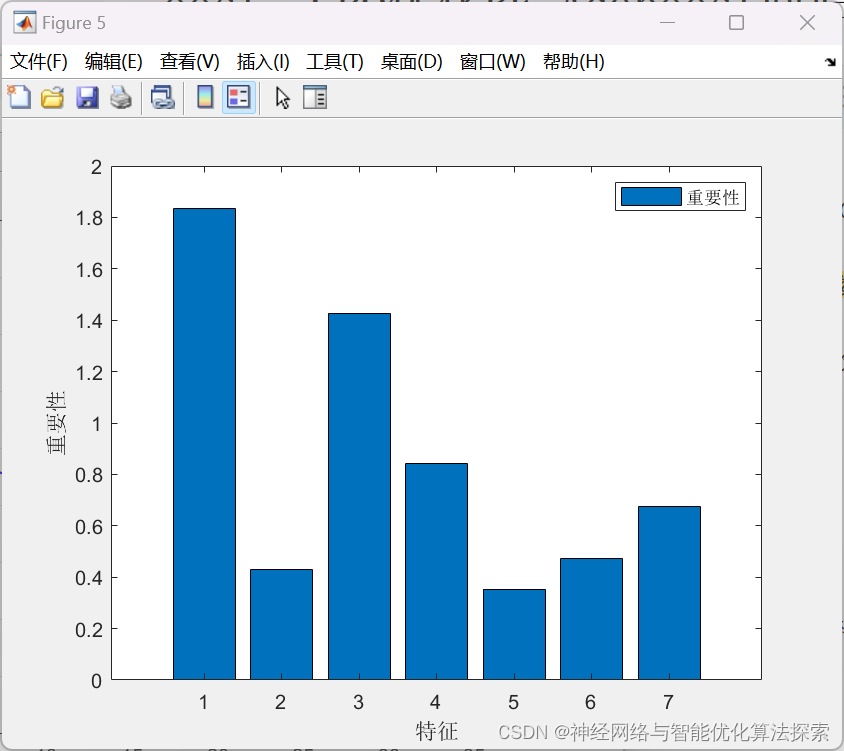
2024年新算法-冠豪猪优化算法(CPO),CPO-RF-Adaboost,CPO优化随机森林RF-Adaboost回归预测-附代码
冠豪猪优化算法(CPO)是一种基于自然界中猪群觅食行为启发的优化算法。该算法模拟了猪群在寻找食物时的集群行为,通过一系列的迭代过程来优化目标函数,以寻找最优解。在这个算法中,猪被分为几个群体,每个群体…

基于随机森林的乳腺癌诊断
在当今的现实生活中存在着很多种微信息量的数据,如何采集这些数据中的信息并进行利用,成了数据分析领域里一个新的研究热点。随机森林以它自身固有的特点和优良的分类效果在众多的机器学习算法中脱颖而出。 随机森林算法由Leo Breiman和 Adele Cutler提出,该算法结合了…
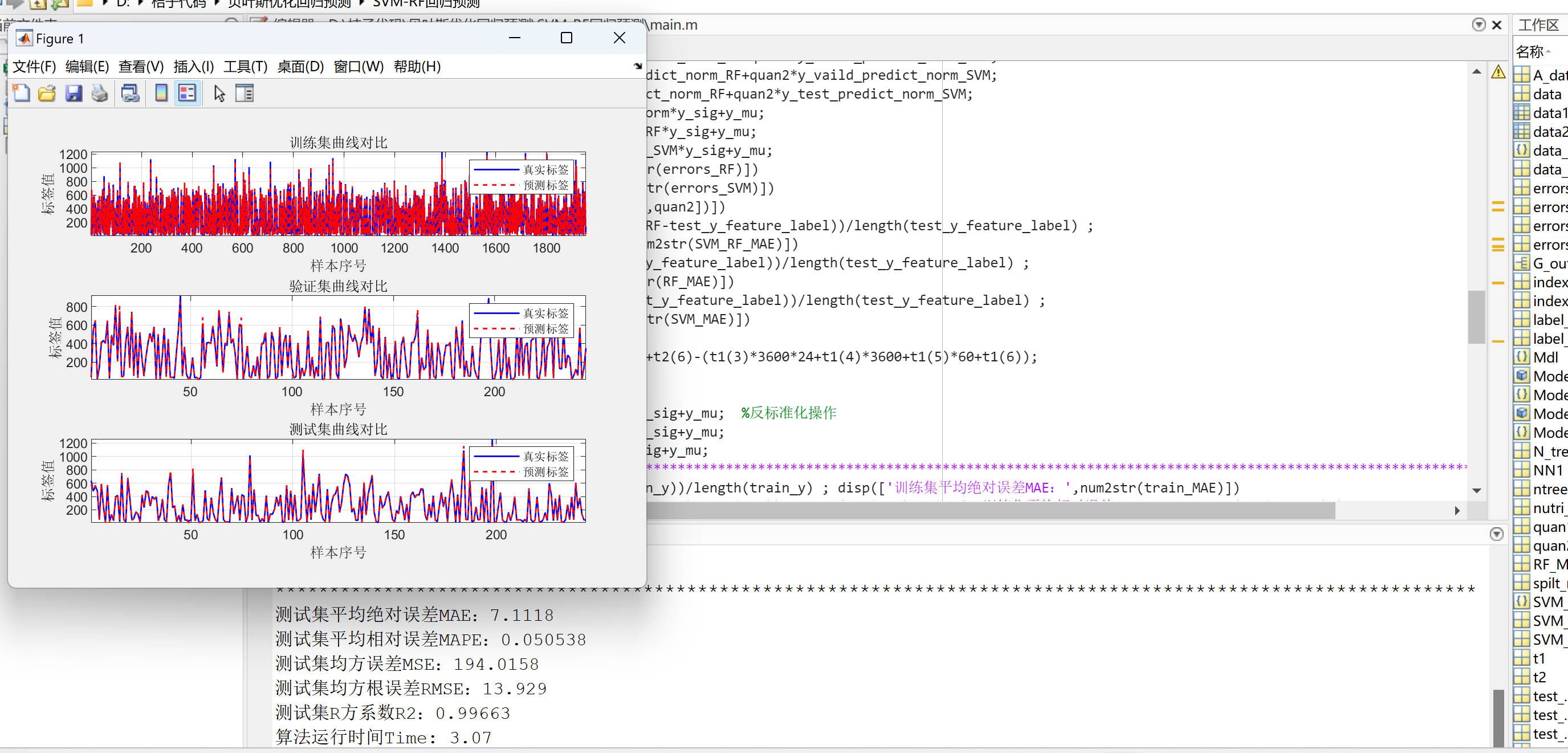
SVM-RF回归预测(matlab代码)
SVM-RF回归预测matlab代码
数据为Excel股票预测数据。
数据集划分为训练集、验证集、测试集,比例为8:1:1
模块化结构: 代码将整个流程模块化,使得代码更易于理解和维护。不同功能的代码块被组织成函数或者独立的模块,使得代码逻…
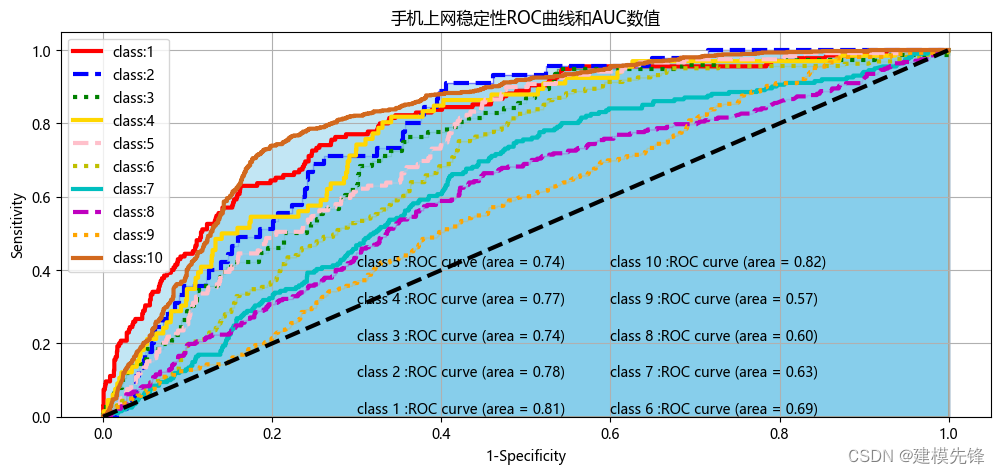
Python绘制多分类ROC曲线
目录
1 数据集介绍
1.1 数据集简介
1.2 数据预处理 2随机森林分类
2.1 数据加载
2.2 参数寻优
2.3 模型训练与评估
3 绘制十分类ROC曲线
第一步,计算每个分类的预测结果概率
第二步,画图数据准备
第三步,绘制十分类ROC曲线 1 数据集…
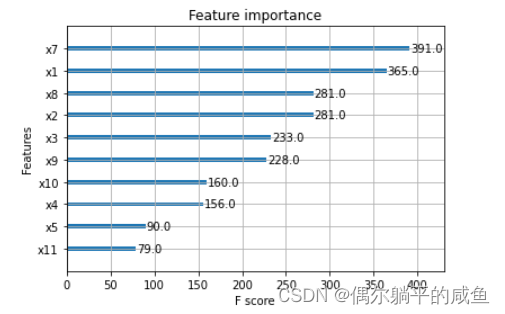
决策树、随机森林、GBDT、XGBoost
文章目录
1. 引入 1.1 决策树1.2 随机森林1.3 GBDT(Gradient Boosting Decision Tree)梯度提升决策树1.4 XGBoost(eXtreme Gradient Boosting)极端梯度提升2. 代码实现 2.1 决策树&随机森林&GBDT&XGBoost 2.1.1 分类2.1.2 回归2.1.3 显示模…

机器学习9-随机森林
随机森林(Random Forest)是一种集成学习方法,用于改善单一决策树的性能,通过在数据集上构建多个决策树并组合它们的预测结果。它属于一种被称为“集成学习”或“集成学习器”的机器学习范畴。 以下是随机森林的主要特点和原理&…
一键批量查询快递单号,一键批量查询,共享备份物流,快递物流尽在掌控
随着网购的普及,快递物流信息的管理变得尤为重要。每天都有大量的快递单号需要查询,如果一个个手动查询,不仅费时费力,还容易出错。为了解决这个问题,我们教您如何批量查询快递单号,并将快递物流信息进行备…

随机森林特征重要性(Variable importance)评估方法
Random Forest Variable importance 算法介绍实现算法流程分类回归 实验实验1:waveform数据集(分类)实验2:superconductivity数据集(回归)实验3:power-consumption数据集(回归&#…

随机森林(袋外OOB数据)
1.在数据抽样的时候,因为是有放回的采样,有很多条样本没有被选到,经过以下计算,
没条样本大概有百分之三十的概率是没有被采样的。 2.对于这些没有被采样到的数据(oob),我们希望能够得到利用当…

【GEE】7、利用GEE进行遥感影像分类【随机森林分类】
1简介 在本模块中,我们将讨论以下概念: 监督和非监督图像分类之间的区别。Google Earth Engine 提供的各种分类算法的定义和应用。如何使用 randomForest 设置和运行分类,以 aspen 存在和不存在作为示例数据集。 2背景 图像分类 人类自然倾向…

机器学习-随机森林【手撕】
随机森林
集成学习算法
概述
集成学习不是一个单独的机器学习算法,而是通过在数据上构建多个模型,集成所有模型的建模结果,基本上现在的所有机器学习都能看到集成学习的身影
目标
综合考虑多个弱评估器的结果,综合得到最终的…

进阶课4——随机森林
1.定义
随机森林是一种集成学习方法,它利用多棵树对样本进行训练并预测。
随机森林指的是利用多棵树对样本进行训练并预测的一种分类器,每棵树都由随机选择的一部分特征进行训练和构建。通过多棵树的集成,可以增加模型的多样性和泛化能力。…
一键批量删除文件名中的空格,轻松整理您的文件
随着数字化时代的到来,我们的电脑里积攒了越来越多的文件,但是随之而来的问题是,文件名中的空格可能会导致一些不便和混乱。为了解决这一问题,我们开发了一款便捷实用的工具,可以一键批量删除文件名中的空格࿰…

机器学习实战——基于Scikit-Learn和TensorFlow 阅读笔记 之 第七章:集成学习和随机森林
《机器学习实战——基于Scikit-Learn和TensorFlow》 这是一本非常好的机器学习和深度学习入门书,既有基本理论讲解,也有实战代码示例。 我将认真阅读此书,并为每一章内容做一个知识笔记。 我会摘录一些原书中的关键语句和代码,若有…
Python量化交易05——基于多因子选择和选股策略(随机森林,LGBM)
参考书目:深入浅出Python量化交易实战 在机器学习里面的X叫做特征变量,在统计学里面叫做协变量也叫自变量,在量化投资里面则叫做因子,所谓多因子就是有很多的特征变量。
本次带来的就是多因子模型,并且使用的是机器学习的强大的非…

机器学习第九课--随机森林
一.什么是集成模型
对于几乎所有的分类问题(图像识别除外,因为对于图像识别问题,目前深度学习是标配),集成模型很多时候是我们的首选。比如构建一个评分卡系统,业界的标配是GBDT或者XGBoost等集成模型,主要因为它的效…

【机器学习】基于机器学习的分类算法对比实验
摘要
基于机器学习的分类算法对比实验
本论文旨在对常见的分类算法进行综合比较和评估,并探索它们在机器学习分类领域的应用。实验结果显示,随机森林模型在CIFAR-10数据集上的精确度为0.4654,CatBoost模型为0.4916,XGBoost模型为…
spss--因子分析案例介绍
这篇文章向大家介绍一个因子分析的实践操作案例。
这篇文章使用的数据集来自于一份问卷,数据集包括31个题目,178个观测(因子分析对观测数有规定,一般要求观测的记录数为题目数量的5到10倍,至少5倍,此数据集…

企业所得税高是怎么回事?该如何解决?
企业所得税高是怎么回事?该如何解决?
《税筹顾问》专注于园区招商、企业税务筹划,合理合规助力企业节税! 企业所得税高,一般企业都会运用一些税务筹划的方式来解决,那么事前的规划和搭建好业务框架就显得尤为重要。真…
机器学习——随机森林算法(RandomForest)
随机森林算法学习
最近在做kaggle的时候,发现随机森林这个算法在分类问题上效果十分的好,大多数情况下效果远要比svm,log回归,knn等算法效果好。因此想琢磨琢磨这个算法的原理。
要学随机森林,首先先简单介绍一下集成…
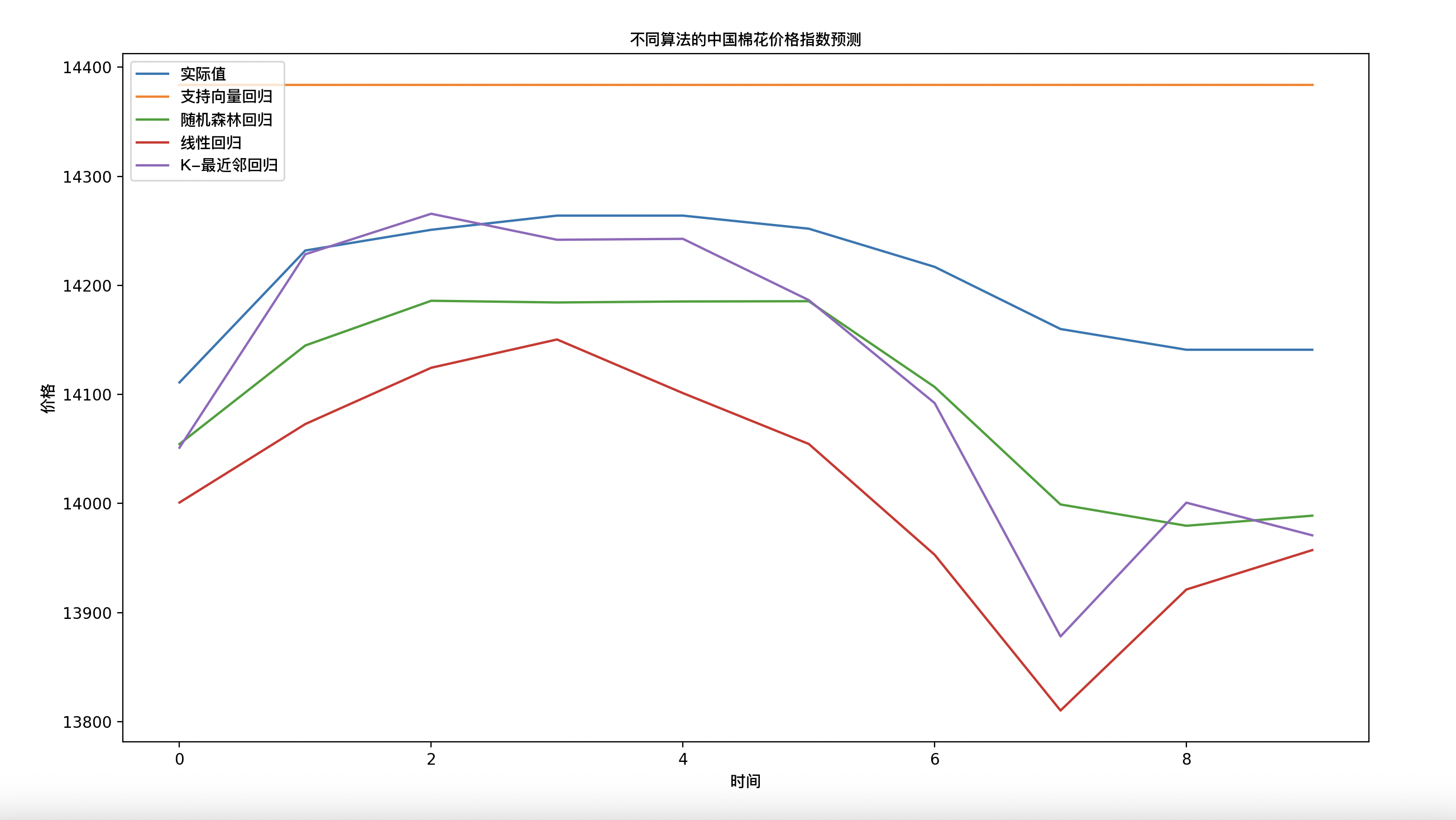
通过向量回归、随机森林回归、线性回归和K-最近邻回归将预测结果绘制成图表进行展示
文章目录 表格部分数据如下运行效果如下代码解析完整代码附件 表格部分数据如下 附件里会给出全部数据链接
运行效果如下 代码解析
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontPropertiesfont FontP…
【机器学习教程】四、随机森林:从论文到实践
引言
随机森林(Random Forest)是机器学习领域中一种强大的集成学习算法。它的优秀性能和广泛应用使得它成为了机器学习领域的一个重要里程碑。本文将从算法的发展历程、重要论文、原理以及实际应用等方面详细介绍随机森林,并提供一个复杂的实战案例。
算法发展和重要论文 …

公司采购缺进项发票,税负重?买票违法不可取,这招可合规节税!
公司采购缺进项发票,税负重?买票违法不可取,这招可合规节税!
《税筹顾问》专注于园区招商,您的贴身节税小能手,合理合规节税! 自从金税四期的上线,我国的税务环境有了翻天覆地的变化…
R语言数据挖掘:随机森林(1)
数据集heart_learning.csv与heart_test.csv是关于心脏病的数据集,heart_learning.csv是训练数据集,heart_test.csv是测试数据集。要求:target和target2为因变量,其他诸变量为自变量。用决策树模型对target和target2做预测…
机器学习和神经网络8
在人工智能领域,神经网络和随机森林是两种强大的机器学习算法。神经网络,特别是深度学习网络,因其在图像和语音识别等复杂任务中的卓越性能而闻名。另一方面,随机森林是一种基于决策树的集成学习技术,它在处理分类和回…
机器学习:随机森林算法
随机森林算法 决策树与随机森林随机森林 决策树与随机森林
随机森林可以看作一个决策树的集合,由n个子训练集得到的决策树组成。
决策树(Decision tree)是一种特殊的树结构,由一个决策图和可能的结果(例如成本和风险…
AMEYA360:北京君正X2600处理器,打造多核异构跨界新价值
伴随下游应用持续丰富,细节需求不断增多,标准化产品已越来越难以满足市场需求,芯片方案提供商需要不断深入行业,根据市场需求推出适配的产品。在这样的背景下,北京君正迅速推出X2600系列多核异构跨界处理器。 据介绍&a…

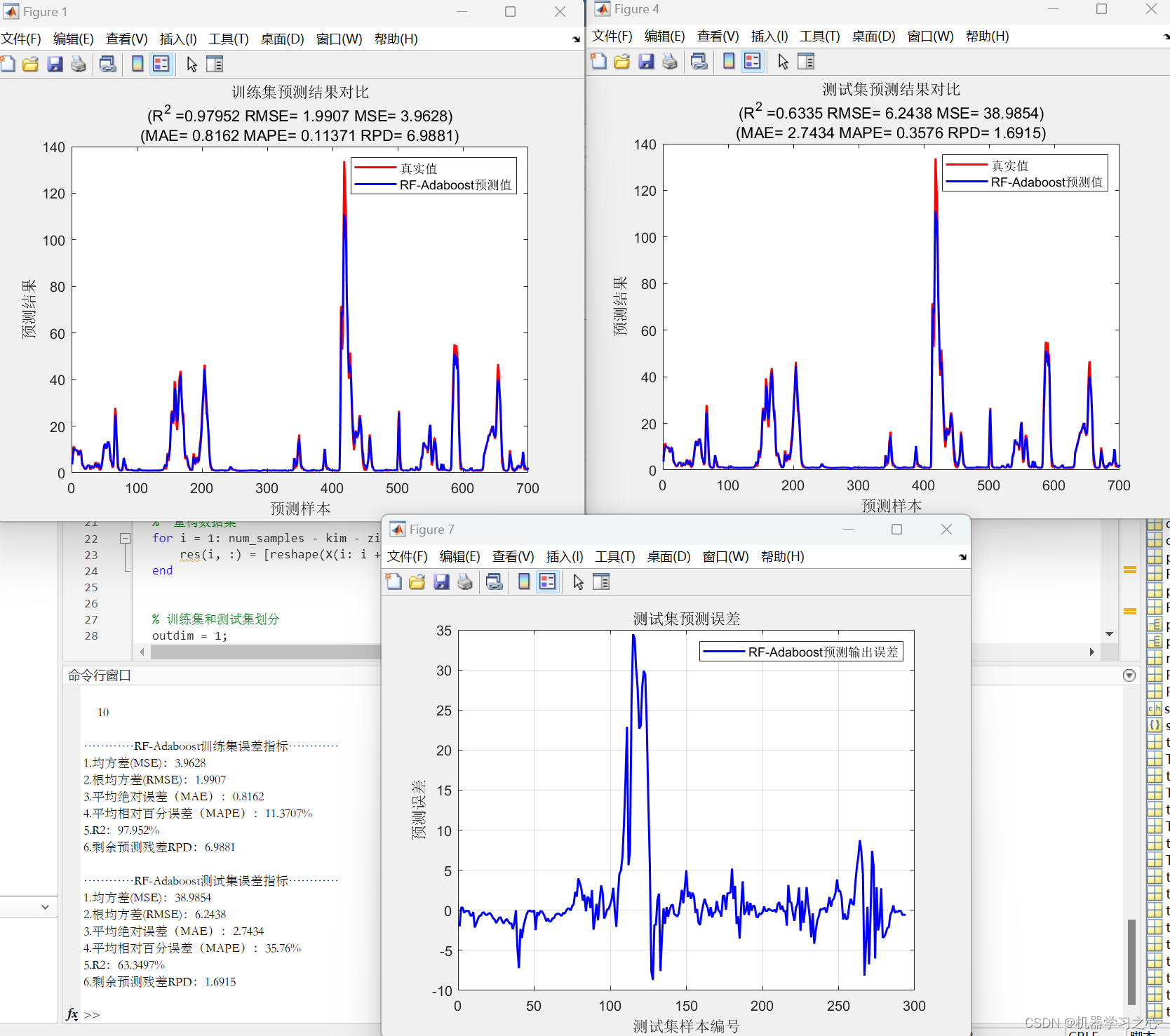
回归预测 | MATLAB实现基于RF-Adaboost随机森林结合AdaBoost多输入单输出回归预测
回归预测 | MATLAB实现基于RF-Adaboost随机森林结合AdaBoost多输入单输出回归预测 目录 回归预测 | MATLAB实现基于RF-Adaboost随机森林结合AdaBoost多输入单输出回归预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.MATLAB实现基于RF-Adaboost随机森林结合…

R语言逻辑回归、决策树、随机森林、神经网络预测患者心脏病数据混淆矩阵可视化...
全文链接:https://tecdat.cn/?p33760 众所周知,心脏疾病是目前全球最主要的死因。开发一个能够预测患者心脏疾病存在的计算系统将显著降低死亡率并大幅降低医疗保健成本。机器学习在全球许多领域中被广泛应用,尤其在医疗行业中越来越受欢迎。机器学习可…
机器学习(十八):Bagging和随机森林
全文共10000余字,预计阅读时间约30~40分钟 | 满满干货(附数据及代码),建议收藏!
本文目标:理解什么是集成学习,明确Bagging算法的过程,熟悉随机森林算法的原理及其在Sklearn中的各参数定义和使用方法 代码…
金融数据_PySpark-3.0.3随机森林(RandomForestClassifier)实例
金融数据_PySpark-3.0.3随机森林(RandomForestClassifier)实例
随机森林 (Random Forest) 和随机森林回归 (Random Forest Regression) 都是基于集成学习的算法, 但它们在任务和输出方面存在一些关键的区别。
随机森林 (Random Forest): 任务类型: 随机森林主要用…
分类算法系列⑥:随机森林
目录
集成学习方法之随机森林
1、集成学习方法
2、随机森林
3、随机森林原理
为什么采用BootStrap抽样
为什么要有放回地抽样
4、API
5、代码
代码解释
结果
6、随机森林总结 🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家…

如何用sklearn对随机森林调参
文章目录 一、概述二、实操1、导入相关包2、导入乳腺癌数据集,建立模型3、调参 三、总结 Link:https://zhuanlan.zhihu.com/p/126288078 Author:陈罐头 一、概述
sklearn是目前python中十分流行的用来实现机器学习的第三方包,其中…

决策树建树及参数调优策略实战
%matplotlib inline import matplotlib.pyplot as plt import pandas as pd
#引入数据
from sklearn.datasets.california_housing import fetch_california_housing housing fetch_california_housing() print(housing.DESCR)
#导入sklearn 建树包 fit(x,y) x:训练样本 …
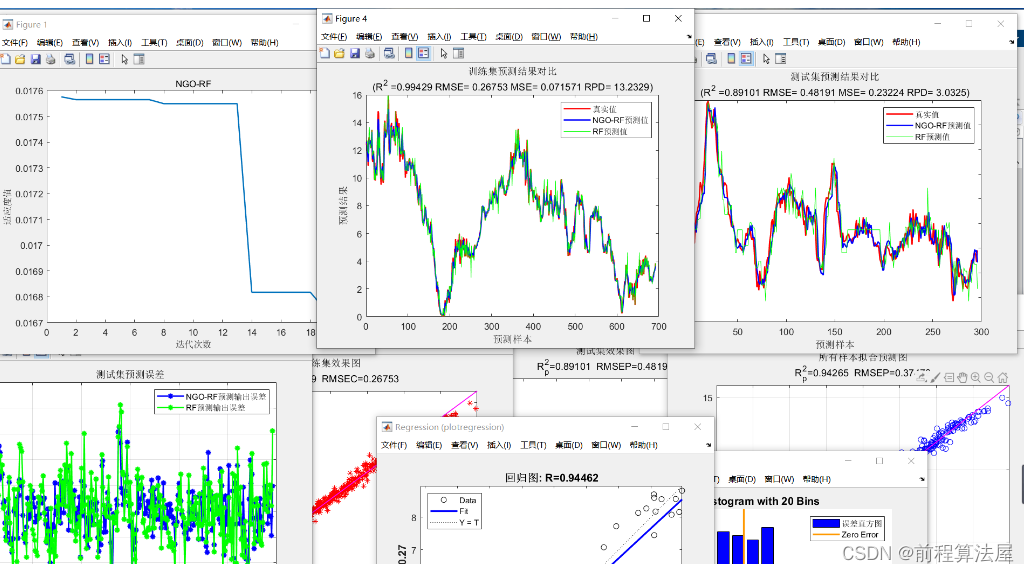
【数据挖掘与商务智能决策】第九章 随机森林模型
9.1.3 随机森林模型的代码实现
和决策树模型一样,随机森林模型既可以做分类分析,也可以做回归分析。
分别对应的模型为随机森林分类模型(RandomForestClassifier)及随机森林回归模型(RandomForestRegressorÿ…

Bagging与随机森林
前今天整理了决策树的原理实现,顺手再把随机森林的原理整理整理。
1.Bagging Bagging是并行式集成学习方法最著名的代表,其原理是给定包含m个样本的数据集,我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集(有放回)…

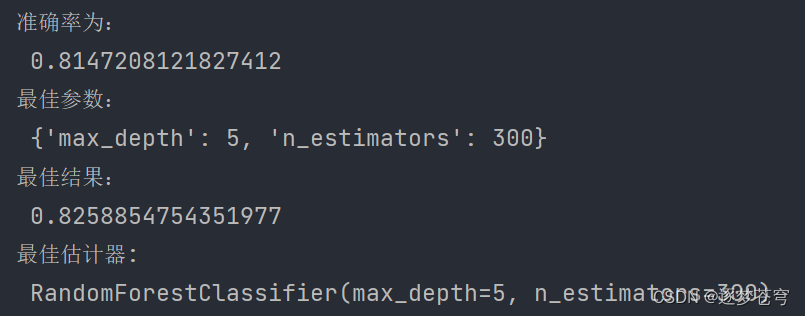
机器学习网格搜索超参数优化实战(随机森林) ##4
文章目录 基于Kaggle电信用户流失案例数据(可在官网进行下载)数据预处理模块时序特征衍生第一轮网格搜索第二轮搜索第三轮搜索第四轮搜索第五轮搜索 基于Kaggle电信用户流失案例数据(可在官网进行下载)
导入库
# 基础数据科学运…

机器学习算法-随机森林
目录
机器学习算法-随机森林
(1)构建单棵决策树。
决策树的构建过程
决策树的构建一般包含三个部分:特征选择、树的生成、剪枝。
机器学习算法-随机森林 机器学习算法-随机森林
随机森林是一种监督式学习算法,适用于分类和回…

肌营养不良患者生活质量的“提升”
肌营养不良患者基本上是生活无法自理的,那么作为肌营养不良患者的家属,提升病人的生活质量就迫在眉睫。看了这篇文章你就知道该怎么做了。 ①保持生活环境整洁
肌营养不良患者本身体质较弱,而且后期会卧病在床,为了防止并发症的发…

随机森林算法与集成学习
随机森林算法与集成学习 – 潘登同学的Machine Learning笔记 文章目录随机森林算法与集成学习 -- 潘登同学的Machine Learning笔记聚合模型同权重不同权重如何生成g(x)g(x)g(x)Bagging(一袋子模型)Boosting(提升模型)随机森林OOB问…
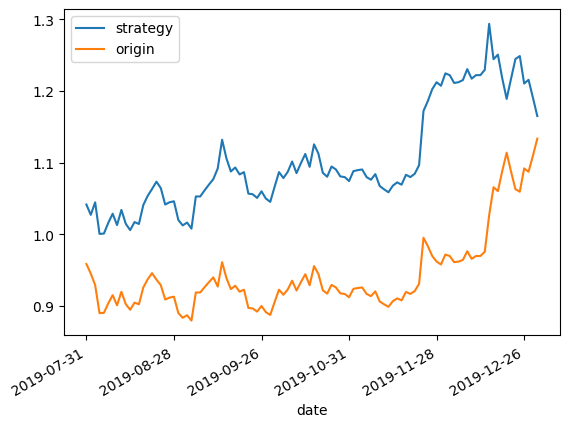
时间序列预测 | Matlab基于北方苍鹰算法优化随机森林(NGO-RF)与随机森林(RF)的时间序列预测对比
文章目录 效果一览文章概述部分源码参考资料效果一览 文章概述 时间序列预测 | Matlab基于北方苍鹰算法优化随机森林(NGO-RF)与随机森林(RF)的时间序列预测对比 评价指标包括:MAE、RMSE和R2等,代码质量极高,方便学习和替换数据。要求2018版本及以上。 部分源码
%-----------…
怎样通俗易懂理解Bagging和随机森林
大家好,我是翔宇!
今天我想和大家聊一聊什么是机器学习中的Bagging思想和随机森林。由于代码实现比较复杂,因此,我没有准备现在进行代码展示,可能后续会有,当然我这里说的代码实现不是指掉包使用ÿ…
GBDT减少模型偏差、随机森林减小模型方差
1、Adaboost算法原理,优缺点:
理论上任何学习器都可以用于Adaboost.但一般来说,使用最广泛的Adaboost弱学习器是决策树和神经网络。对于决策树,Adaboost分类用了CART分类树,而Adaboost回归用了CART回归树。
Adaboost…
机械学习模型训练常用代码(随机森林、聚类、逻辑回归、svm、线性回归、lasso回归,岭回归)
一、数据处理(特征工程)
更多pandas操作请参考添加链接描述pandas对于文件数据基本操作 导入的包sklearn
pip3 install --index-url https://pypi.douban.com/simple scikit-learn缺失值处理
#缺失值查看
df.replace(NaN , np.nan, inplaceTrue)#将数…
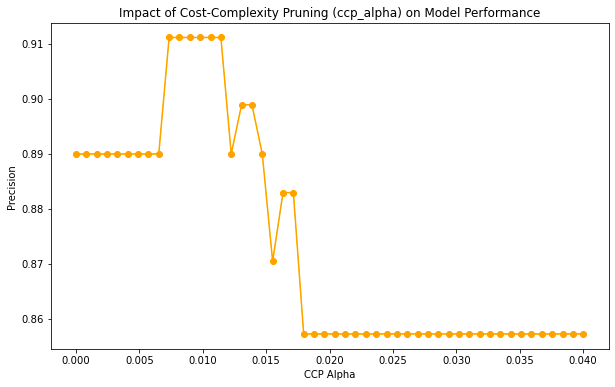
从根到叶:随机森林模型的深入探索
一、说明 在本综合指南中,我们将超越基础知识。当您盯着随机森林模型的文档时,您将不再对“节点杂质”、“加权分数”或“成本复杂性修剪”等术语感到不知所措。相反,我们将剖析每个参数,阐明其作用和影响。通过理论和 Python 实践…

树——“数据结构与算法”
各位CSDN的uu们好久不见呀,好久没有更新我的数据结构与算法专栏啦,现在,我要开始重拾丢下的知识啦,这次,小雅兰要给uu们介绍一个全新的数据结构,下面,就让我们进入树的世界吧!&#…
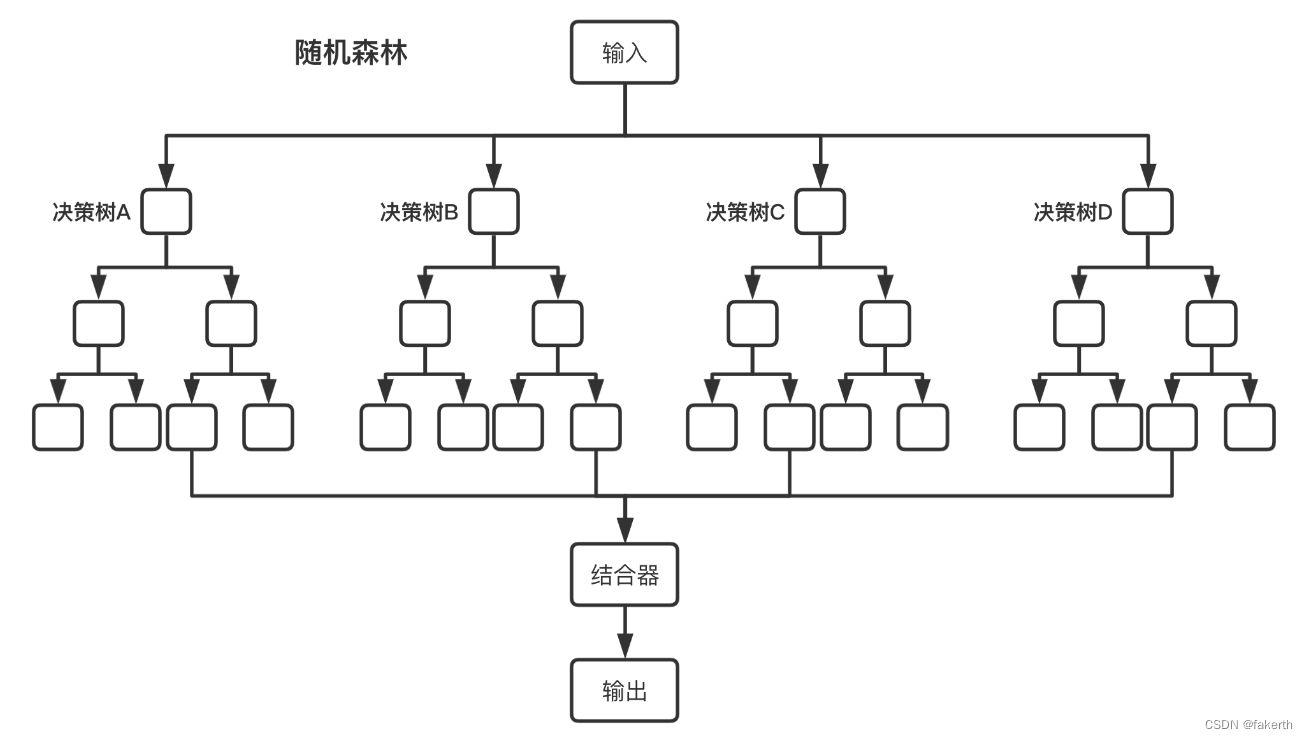
决策树、随机森林可视化
分享一个Python可视化工具pybaobabdt,轻松对决策树、随机森林可视化,例如, 图怎么看:每一种颜色代表一个class,link的宽度表示从一个节点流向另一个节点的items数量。 安装
pip install pybaobabdt
pip install pygra…
随机森林(Random Forest)原理解析:从集成学习到决策树集合
目录 1. 集成学习2. 决策树集合3. 随机森林的预测4. 随机森林优缺点5. 随机森林代码实例 随机森林是一种强大且常用的机器学习算法,它通过集成学习的思想将多个决策树组合成一个强大的分类或回归模型。本文将详细解析随机森林的原理,从集成学习到决策树集…

【Sklearn】基于随机森林算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于随机森林算法的数据分类预测(Excel可直接替换数据) 1.模型原理1.1 模型原理1.2 数学模型 2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果 1.模型原理
随机森林(Random Forest)是一种集成学习方法…

基于随机森林实现特征选择降维及回归预测(Matlab代码实现)
目录 摘要: 1.随机森林: 2.随机森林的特征选取: 3.基于Matlab自带的随机森林函数进行特征选取具体步骤 (1)加载数据 (2)首先建立随机森林并使用全部特征进行车辆经济性预测 (3&#…

决策树、随机森林、极端随机树(ERT)
声明:本文仅为个人学习记录所用,参考较多,如有侵权,联系删除
决策树
通俗来说,决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话: 女儿&#x…
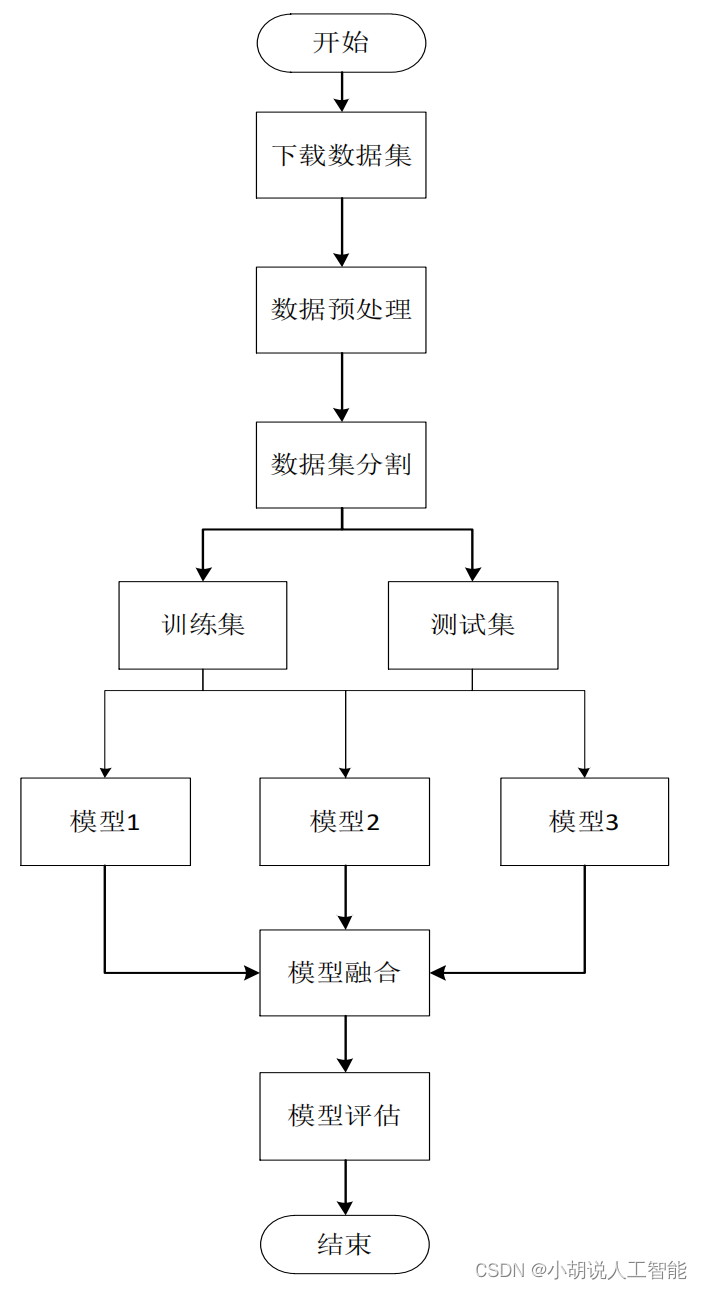
基于Python机器学习算法小分子药性预测(岭回归+随机森林回归+极端森林回归+加权平均融合模型)
目录 前言总体设计系统整体结构图系统流程图 运行环境Python 环境配置工具包 模块实现1. 数据预处理2. 创建模型并编译3. 模型训练 系统测试工程源代码下载其它资料下载 前言
《麻省理工科技评论》于2020年发布了“十大突破性技术”预测,其中包括“AI药物分子发现”…
集成学习-随机森林原理与实现 西瓜书
多样性增强 在讲随机森林之前,先讨论一下多样性增强.在集成学习中需要有效的生成多样性大的个体学习器,与构造单一学习器对比而言,一般是通过在学习过程中引入随机性,常见的做法是对数据样本,输入属性,输出…
XGB-11:随机森林
XGBoost通常用于训练梯度提升决策树和其他梯度提升模型。随机森林使用与梯度提升决策树相同的模型表示和推断,但使用不同的训练算法。可以使用XGBoost来训练独立的随机森林,或者将随机森林作为梯度提升的基模型。这里我们专注于训练独立的随机森林。
XG…